Previous module |
Next module
Module #822, TG: 2.6, TC: 1.2, 112 probes, 112 Entrez genes, 10 conditions


HELP
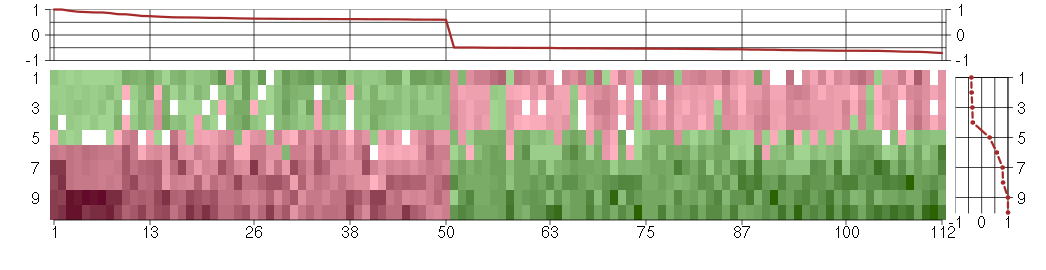
The image plot shows the color-coded level of gene expression, for the
genes and conditions in a given transcription module. The genes are on
the horizontal, the conditions on the vertical axis.
The genes are ordered according to their ISA gene scores, similarly
the conditions are ordered according to their condition scores. The
score of a gene means the «degree of inclusion» in
the module: a high score gene is essential in the module.
Condition scores can also be negative, that means that the genes of
the module are all down-regulated in the condition. Here the absolute
value of the score gives the «degree of inclusion».
The plots above and beside the expression matrix show the gene scores
and condition scores, respectively.
Note that the plot is interactive, you can see the name of the gene
and condition under the mouse cursor.
The expression matrix was normalized to have mean zero and standard
deviation one for every gene separately across all conditions
(i.e. not just for the conditions in the module).
— Click on the Help button again to close this help window.

Under-expression is coded with green,
over-expression with red color.
Help |
Hide |
Top
Help |
Show |
Top
The GO tree — Biological processes
HELP
This is one of three sections showing Gene Ontology enrichment of the
current module: in this case for biological processes.
The graph shows the hierarchy of the GO categories, their enrichment
for the current module is color coded, and the blue number beside the
category is the minus log ten p-value of the enrichment. (Calculated
using the standard hypergeometric test.) The color of the arrows code
«is a» (cyan) and «part of» relationships.
The tree was built the following way. First all GO terms with more
significant enrichment p-value than 0.05 were collected. Then all
paths from these terms to the root node of the GO tree were included
too. If a GO term is included more than once in the tree, then the
green numbers show 1) the id of the node, this makes it easier to find
other appereances of the term, and 2) the number of appearences.
Note that the same GO category might show up on the graph many
times. This is because the GO was «straightened» for this
graph, i.e. if there are more paths from a GO term to the root node of
the tree, all of them are included. The green numbers
Move the mouse cursor over the terms to get their definition. Clicking
on them takes you to the corresponding Gene Ontology web page.
If you cannot see a graph here at all, that means that there were no
significantly enriched GO categories, at the 0.05 level.
— Click on the Help button again to close this help window.

biological_process
Any process specifically pertinent to the functioning of integrated living units: cells, tissues, organs, and organisms. A process is a collection of molecular events with a defined beginning and end.
response to endogenous stimulus
A change in state or activity of a cell or an organism (in terms of movement, secretion, enzyme production, gene expression, etc.) as a result of a stimulus arising within the organism.
response to hormone stimulus
A change in state or activity of a cell or an organism (in terms of movement, secretion, enzyme production, gene expression, etc.) as a result of a hormone stimulus.
response to chemical stimulus
A change in state or activity of a cell or an organism (in terms of movement, secretion, enzyme production, gene expression, etc.) as a result of a chemical stimulus.
response to steroid hormone stimulus
A change in state or activity of a cell or an organism (in terms of movement, secretion, enzyme production, gene expression, etc.) as a result of a steroid hormone stimulus.
response to stimulus
A change in state or activity of a cell or an organism (in terms of movement, secretion, enzyme production, gene expression, etc.) as a result of a stimulus.
all
This term is the most general term possible
response to hormone stimulus
A change in state or activity of a cell or an organism (in terms of movement, secretion, enzyme production, gene expression, etc.) as a result of a hormone stimulus.
Help |
Hide |
Top
Help |
Show |
Top
The GO tree — Cellular Components
HELP
This is one of three sections showing Gene Ontology enrichment of the
current module: in this case for cellular components.
The graph shows the hierarchy of the GO categories, their enrichment
for the current module is color coded, and the blue number beside the
category is the minus log ten p-value of the enrichment. (Calculated
using the standard hypergeometric test.) The color of the arrows code
«is a» (cyan) and «part of» relationships.
The tree was built the following way. First all GO terms with more
significant enrichment p-value than 0.05 were collected. Then all
paths from these terms to the root node of the GO tree were included
too. If a GO term is included more than once in the tree, then the
green numbers show 1) the id of the node, this makes it easier to find
other appereances of the term, and 2) the number of appearences.
Note that the same GO category might show up on the graph many
times. This is because the GO was «straightened» for this
graph, i.e. if there are more paths from a GO term to the root node of
the tree, all of them are included. The green numbers
Move the mouse cursor over the terms to get their definition. Clicking
on them takes you to the corresponding Gene Ontology web page.
If you cannot see a graph here at all, that means that there were no
significantly enriched GO categories, at the 0.05 level.
— Click on the Help button again to close this help window.
Help |
Hide |
Top
Help |
Show |
Top
The GO tree — Molecular Function
HELP
This is one of three sections showing Gene Ontology enrichment of the
current module: in this case for molecular function.
The graph shows the hierarchy of the GO categories, their enrichment
for the current module is color coded, and the blue number beside the
category is the minus log ten p-value of the enrichment. (Calculated
using the standard hypergeometric test.) The color of the arrows code
«is a» (cyan) and «part of» relationships.
The tree was built the following way. First all GO terms with more
significant enrichment p-value than 0.05 were collected. Then all
paths from these terms to the root node of the GO tree were included
too. If a GO term is included more than once in the tree, then the
green numbers show 1) the id of the node, this makes it easier to find
other appereances of the term, and 2) the number of appearences.
Note that the same GO category might show up on the graph many
times. This is because the GO was «straightened» for this
graph, i.e. if there are more paths from a GO term to the root node of
the tree, all of them are included. The green numbers
Move the mouse cursor over the terms to get their definition. Clicking
on them takes you to the corresponding Gene Ontology web page.
If you cannot see a graph here at all, that means that there were no
significantly enriched GO categories, at the 0.05 level.
— Click on the Help button again to close this help window.
Help |
Hide |
Top
Help |
Show |
Top
GO BP test for over-representation
HELP
List of all enriched GO categories (biological processes), at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module annotated with the given GO term, just by chance.
- Count
is the number of genes in the module annotated with the given GO
term.
- Size is the total number of genes (in our universe)
annotated with the GO term.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
GO category.
Clicking on the GO identifiers takes you to the Gene Ontology web
pages.
— Click on the Help button again to close this help window.
| Id | Pvalue | ExpCount | Count | Size | Term |
| GO:0048545 | 6.440e-03 | 0.4268 | 5
CD24, FAS, GATA3, KRT19, UGT1A1 | 37 | response to steroid hormone stimulus |
| GO:0009725 | 2.217e-02 | 0.9227 | 6
CD24, FAS, GATA3, IRS2, KRT19, UGT1A1 | 80 | response to hormone stimulus |
| GO:0006805 | 2.687e-02 | 0.1499 | 3
UGT1A1, UGT1A6, UGT1A9 | 13 | xenobiotic metabolic process |
| GO:0019896 | 2.698e-02 | 0.0346 | 2
NEFL, UCHL1 | 3 | axon transport of mitochondrion |
| GO:0009719 | 3.074e-02 | 1.003 | 6
CD24, FAS, GATA3, IRS2, KRT19, UGT1A1 | 87 | response to endogenous stimulus |
| GO:0009410 | 4.162e-02 | 0.1845 | 3
UGT1A1, UGT1A6, UGT1A9 | 16 | response to xenobiotic stimulus |
Help |
Hide |
Top
Help |
Show |
Top
GO CC test for over-representation
HELP
List of all enriched GO categories (cellular components), at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module annotated with the given GO term, just by chance.
- Count
is the number of genes in the module annotated with the given GO
term.
- Size is the total number of genes (in our universe)
annotated with the GO term.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
GO category.
Clicking on the GO identifiers takes you to the Gene Ontology web
pages.
— Click on the Help button again to close this help window.
| Id | Pvalue | ExpCount | Count | Size | Term |
| GO:0005578 | 1.366e-02 | 1.821 | 8
COL11A1, COMP, CRTAP, FBN2, LTBP2, MFAP5, SNCA, TIMP2 | 153 | proteinaceous extracellular matrix |
| GO:0031012 | 1.961e-02 | 1.94 | 8
COL11A1, COMP, CRTAP, FBN2, LTBP2, MFAP5, SNCA, TIMP2 | 163 | extracellular matrix |
| GO:0005576 | 4.997e-02 | 8.01 | 17
APOL3, C3orf64, C4orf31, COL11A1, COMP, CRTAP, FAM108A1, FAS, FBN2, GAS6, ISLR, KIAA0495, LTBP2, MFAP5, NMU, SNCA, TIMP2 | 673 | extracellular region |
Help |
Hide |
Top
Help |
Show |
Top
GO MF test for over-representation
HELP
List of all enriched GO categories (molecular function), at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module annotated with the given GO term, just by chance.
- Count
is the number of genes in the module annotated with the given GO
term.
- Size is the total number of genes (in our universe)
annotated with the GO term.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
GO category.
Clicking on the GO identifiers takes you to the Gene Ontology web
pages.
— Click on the Help button again to close this help window.
| Id | Pvalue | ExpCount | Count | Size | Term |
| GO:0015020 | 2.882e-02 | 0.1385 | 3
UGT1A1, UGT1A6, UGT1A9 | 12 | glucuronosyltransferase activity |
Help |
Hide |
Top
Help |
Show |
Top
KEGG Pathway test for over-representation
HELP
List of all enriched KEGG pathways, at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module annotated with the given KEGG pathway, just by chance.
- Count
is the number of genes in the module annotated with the given KEGG
pathway.
- Size is the total number of genes (in our universe)
annotated with the KEGG pathway.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
KEGG pathway.
Clicking on the KEGG identifiers takes you to the KEGG web site.
— Click on the Help button again to close this help window.
| Id | Pvalue | ExpCount | Count | Size | Term |
| 00040 | 1.850e-02 | 0.1306 | 3
UGT1A1, UGT1A6, UGT1A9 | 13 | Pentose and glucuronate interconversions |
Help |
Hide |
Top
Help |
Show |
Top
miRNA test for over-representation
HELP
List of all enriched miRNA families, at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module regulated by the given miRNA family, just by chance.
- Count
is the number of genes in the module regulated by the given miRNA
family.
- Size is the total number of genes (in our universe)
regulated with the given miRNA family.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
miRNA family.
The miRNA regulation data was taken from the TargetScan database.
(Only the conserved sites were used for the current analysis.)
Clicking on the miRNA names takes you to the TargetScan web site.
— Click on the Help button again to close this help window.
Help |
Hide |
Top
Help |
Show |
Top
Chromosome test for over-representation
HELP
List of all enriched Chromosomes, at the 0.05
p-value level.
The columns:
- ExpCount is the expected number of genes in the
module on the given chromosome, just by chance.
- Count
is the number of genes in the module on the given chromosome.
- Size is the total number of genes (in our universe)
on the given chromosome.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
chromosome.
— Click on the Help button again to close this help window.
HELP
A list of all genes in the current module, in alphabetical order. The
size of the text corresponds to the gene scores.
Note that some gene symbols may show up more than once, if many
probes match the same Entrez gene.
Genes with no Entrez mapping are given separately, with their
Affymetrics probe ID.
— Click on the Help button again to close this help window.
Entrez genes
ABCB1ATP-binding cassette, sub-family B (MDR/TAP), member 1 (209993_at), score: 1
ABHD14Aabhydrolase domain containing 14A (210006_at), score: -0.52
AIM2absent in melanoma 2 (206513_at), score: 0.67
AKAP8LA kinase (PRKA) anchor protein 8-like (218064_s_at), score: 0.63
APOL3apolipoprotein L, 3 (221087_s_at), score: 0.6
BAZ2Abromodomain adjacent to zinc finger domain, 2A (201353_s_at), score: 0.67
BHMT2betaine-homocysteine methyltransferase 2 (219902_at), score: 0.64
C10orf116chromosome 10 open reading frame 116 (203571_s_at), score: -0.66
C20orf149chromosome 20 open reading frame 149 (218010_x_at), score: -0.52
C3orf64chromosome 3 open reading frame 64 (221935_s_at), score: -0.55
C4orf31chromosome 4 open reading frame 31 (219747_at), score: -0.62
C5orf23chromosome 5 open reading frame 23 (219054_at), score: -0.51
C5orf30chromosome 5 open reading frame 30 (221823_at), score: -0.6
CD24CD24 molecule (266_s_at), score: 0.62
CDR2Lcerebellar degeneration-related protein 2-like (213230_at), score: -0.56
CLINT1clathrin interactor 1 (201768_s_at), score: 0.6
COL11A1collagen, type XI, alpha 1 (37892_at), score: -0.53
COMPcartilage oligomeric matrix protein (205713_s_at), score: -0.5
COPZ2coatomer protein complex, subunit zeta 2 (219561_at), score: -0.49
CRTAPcartilage associated protein (201380_at), score: -0.58
CRYABcrystallin, alpha B (209283_at), score: -0.67
DDX17DEAD (Asp-Glu-Ala-Asp) box polypeptide 17 (208151_x_at), score: 0.81
DDX3XDEAD (Asp-Glu-Ala-Asp) box polypeptide 3, X-linked (201211_s_at), score: 0.63
DGKDdiacylglycerol kinase, delta 130kDa (208072_s_at), score: 0.65
DUSP14dual specificity phosphatase 14 (203367_at), score: -0.56
EPHB2EPH receptor B2 (209589_s_at), score: 0.64
FAM108A1family with sequence similarity 108, member A1 (221267_s_at), score: -0.53
FAM169Afamily with sequence similarity 169, member A (213954_at), score: 0.74
FASFas (TNF receptor superfamily, member 6) (204780_s_at), score: -0.53
FAT1FAT tumor suppressor homolog 1 (Drosophila) (201579_at), score: -0.66
FBN2fibrillin 2 (203184_at), score: -0.54
FKBP4FK506 binding protein 4, 59kDa (200894_s_at), score: 0.61
FKBP9FK506 binding protein 9, 63 kDa (212169_at), score: -0.69
GABREgamma-aminobutyric acid (GABA) A receptor, epsilon (204537_s_at), score: 0.63
GAGE4G antigen 4 (207086_x_at), score: 0.95
GAGE6G antigen 6 (208155_x_at), score: 0.91
GAS6growth arrest-specific 6 (202177_at), score: -0.52
GATA3GATA binding protein 3 (209604_s_at), score: 0.82
GLSglutaminase (203159_at), score: -0.58
GLTPglycolipid transfer protein (219267_at), score: -0.55
HAS2hyaluronan synthase 2 (206432_at), score: -0.56
HERC5hect domain and RLD 5 (219863_at), score: 0.75
HGSNATheparan-alpha-glucosaminide N-acetyltransferase (218017_s_at), score: -0.61
HIST1H4Chistone cluster 1, H4c (205967_at), score: -0.5
HSPB2heat shock 27kDa protein 2 (205824_at), score: -0.51
HSPB7heat shock 27kDa protein family, member 7 (cardiovascular) (218934_s_at), score: -0.65
IPO8importin 8 (205701_at), score: 0.62
IRS2insulin receptor substrate 2 (209185_s_at), score: -0.53
ISLRimmunoglobulin superfamily containing leucine-rich repeat (207191_s_at), score: -0.52
KIAA0495KIAA0495 (213340_s_at), score: -0.52
KRT19keratin 19 (201650_at), score: -0.54
LDOC1leucine zipper, down-regulated in cancer 1 (204454_at), score: -0.5
LEF1lymphoid enhancer-binding factor 1 (221558_s_at), score: 0.63
LOC388796hypothetical LOC388796 (65588_at), score: 0.61
LOC728855hypothetical LOC728855 (222001_x_at), score: 0.65
LRRC2leucine rich repeat containing 2 (219949_at), score: -0.57
LTBP2latent transforming growth factor beta binding protein 2 (204682_at), score: -0.53
MAN2A1mannosidase, alpha, class 2A, member 1 (205105_at), score: -0.64
MARCH2membrane-associated ring finger (C3HC4) 2 (210075_at), score: -0.53
MARK1MAP/microtubule affinity-regulating kinase 1 (221047_s_at), score: 0.72
MFAP5microfibrillar associated protein 5 (213764_s_at), score: -0.63
MYO1Cmyosin IC (214656_x_at), score: -0.62
NCRNA00084non-protein coding RNA 84 (214657_s_at), score: 0.69
NDNnecdin homolog (mouse) (209550_at), score: -0.49
NEFLneurofilament, light polypeptide (221805_at), score: 0.69
NEK7NIMA (never in mitosis gene a)-related kinase 7 (212530_at), score: -0.49
NGDNneuroguidin, EIF4E binding protein (213794_s_at), score: 0.6
NMUneuromedin U (206023_at), score: 0.62
NONOnon-POU domain containing, octamer-binding (208698_s_at), score: 0.66
NRGNneurogranin (protein kinase C substrate, RC3) (204081_at), score: 0.62
OASL2'-5'-oligoadenylate synthetase-like (210797_s_at), score: 1
PILRBpaired immunoglobin-like type 2 receptor beta (220954_s_at), score: 0.69
PPM2Cprotein phosphatase 2C, magnesium-dependent, catalytic subunit (218273_s_at), score: 0.62
PPP1R3Cprotein phosphatase 1, regulatory (inhibitor) subunit 3C (204284_at), score: -0.51
PSMB4proteasome (prosome, macropain) subunit, beta type, 4 (202243_s_at), score: -0.62
PSMB8proteasome (prosome, macropain) subunit, beta type, 8 (large multifunctional peptidase 7) (209040_s_at), score: 0.62
RAB7L1RAB7, member RAS oncogene family-like 1 (218700_s_at), score: 0.63
RABGAP1LRAB GTPase activating protein 1-like (213982_s_at), score: -0.54
RAD23BRAD23 homolog B (S. cerevisiae) (201223_s_at), score: -0.71
RBM3RNA binding motif (RNP1, RRM) protein 3 (222026_at), score: -0.54
RPP14ribonuclease P/MRP 14kDa subunit (204245_s_at), score: 0.6
SART3squamous cell carcinoma antigen recognized by T cells 3 (209127_s_at), score: 0.6
SGCDsarcoglycan, delta (35kDa dystrophin-associated glycoprotein) (213543_at), score: -0.51
SLC16A1solute carrier family 16, member 1 (monocarboxylic acid transporter 1) (209900_s_at), score: -0.51
SLC30A1solute carrier family 30 (zinc transporter), member 1 (212907_at), score: -0.56
SLC4A4solute carrier family 4, sodium bicarbonate cotransporter, member 4 (203908_at), score: -0.61
SMEK1SMEK homolog 1, suppressor of mek1 (Dictyostelium) (220368_s_at), score: 0.64
SMG1SMG1 homolog, phosphatidylinositol 3-kinase-related kinase (C. elegans) (210057_at), score: 0.63
SNCAsynuclein, alpha (non A4 component of amyloid precursor) (204466_s_at), score: 0.78
SSR3signal sequence receptor, gamma (translocon-associated protein gamma) (217790_s_at), score: -0.62
SYTL2synaptotagmin-like 2 (220613_s_at), score: 0.68
TBC1D3TBC1 domain family, member 3 (209403_at), score: 0.63
TCEAL2transcription elongation factor A (SII)-like 2 (211276_at), score: 0.86
TEKTEK tyrosine kinase, endothelial (206702_at), score: -0.49
TIMP2TIMP metallopeptidase inhibitor 2 (203167_at), score: -0.62
TMEM204transmembrane protein 204 (219315_s_at), score: -0.54
TMEM47transmembrane protein 47 (209656_s_at), score: -0.6
TMEM51transmembrane protein 51 (218815_s_at), score: 0.62
TMOD1tropomodulin 1 (203661_s_at), score: 0.67
TNS1tensin 1 (221748_s_at), score: -0.6
TOB1transducer of ERBB2, 1 (202704_at), score: -0.55
TSPAN13tetraspanin 13 (217979_at), score: -0.57
TSPYL5TSPY-like 5 (213122_at), score: -0.59
UAP1UDP-N-acteylglucosamine pyrophosphorylase 1 (209340_at), score: -0.62
UBE2Hubiquitin-conjugating enzyme E2H (UBC8 homolog, yeast) (221962_s_at), score: 0.62
UBL3ubiquitin-like 3 (201535_at), score: -0.59
UCHL1ubiquitin carboxyl-terminal esterase L1 (ubiquitin thiolesterase) (201387_s_at), score: -0.5
UGT1A1UDP glucuronosyltransferase 1 family, polypeptide A1 (207126_x_at), score: 0.88
UGT1A6UDP glucuronosyltransferase 1 family, polypeptide A6 (206094_x_at), score: 0.9
UGT1A9UDP glucuronosyltransferase 1 family, polypeptide A9 (204532_x_at), score: 0.89
WT1Wilms tumor 1 (206067_s_at), score: 0.71
ZNF281zinc finger protein 281 (218401_s_at), score: -0.52
Non-Entrez genes
Unknown, score:
HELP
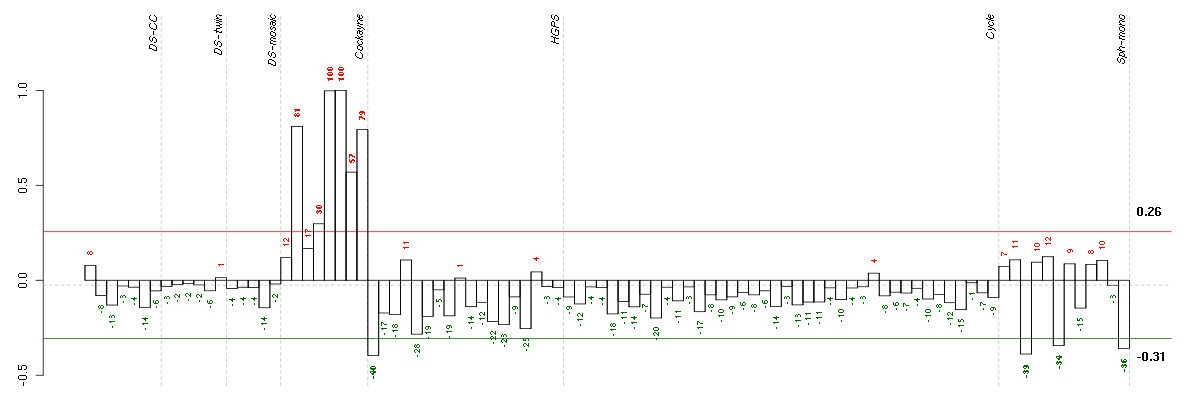
Conditions in the module, given in the same order as on the expression
plot above. Red color means over-expression, green under-expression in
the given condition.
The barplot below shows the condition (sample) scores. A separate bar
is shown for each sample, its height is the corresponding score of the
sample in the module. The red and green numbers on the bars are the
sample scores expressed in percents, i.e. 100% is 1.0.
The red and green lines show the module thresholds, samples above
the red line and below the green line are included in the module.
The different experiments that were part of the study, are separated
by dashed vertical lines.
— Click on the Help button again to close this help window.
| Id | sample | Experiment | ExpName | Array | Syndrome | Cell.line |
| E-GEOD-3860-raw-cel-1561690199.cel | 1 | 5 | HGPS | hgu133a | none | GM0316B |
| E-GEOD-4219-raw-cel-1311956178.cel | 6 | 7 | Sph-mono | hgu133plus2 | none | Sph-mon 1 |
| E-GEOD-4219-raw-cel-1311956824.cel | 24 | 7 | Sph-mono | hgu133plus2 | none | Sph-mon 1 |
| E-GEOD-4219-raw-cel-1311956358.cel | 10 | 7 | Sph-mono | hgu133plus2 | none | Sph-mon 1 |
| E-GEOD-3407-raw-cel-1437949704.cel | 4 | 4 | Cockayne | hgu133a | CS | eGFP |
| E-GEOD-3407-raw-cel-1437949854.cel | 7 | 4 | Cockayne | hgu133a | CS | eGFP |
| E-GEOD-3407-raw-cel-1437949938.cel | 8 | 4 | Cockayne | hgu133a | none | CSB |
| E-GEOD-3407-raw-cel-1437949579.cel | 2 | 4 | Cockayne | hgu133a | none | CSB |
| E-GEOD-3407-raw-cel-1437949721.cel | 5 | 4 | Cockayne | hgu133a | CS | CSB |
| E-GEOD-3407-raw-cel-1437949750.cel | 6 | 4 | Cockayne | hgu133a | CS | CSB |



© 2008-2010 Computational Biology Group, Department of Medical Genetics,
University of Lausanne, Switzerland