Previous module |
Next module
Module #522, TG: 3, TC: 2, 118 probes, 118 Entrez genes, 6 conditions


HELP
The image plot shows the color-coded level of gene expression, for the
genes and conditions in a given transcription module. The genes are on
the horizontal, the conditions on the vertical axis.
The genes are ordered according to their ISA gene scores, similarly
the conditions are ordered according to their condition scores. The
score of a gene means the «degree of inclusion» in
the module: a high score gene is essential in the module.
Condition scores can also be negative, that means that the genes of
the module are all down-regulated in the condition. Here the absolute
value of the score gives the «degree of inclusion».
The plots above and beside the expression matrix show the gene scores
and condition scores, respectively.
Note that the plot is interactive, you can see the name of the gene
and condition under the mouse cursor.
The expression matrix was normalized to have mean zero and standard
deviation one for every gene separately across all conditions
(i.e. not just for the conditions in the module).
— Click on the Help button again to close this help window.

Under-expression is coded with green,
over-expression with red color.
Help |
Hide |
Top
Help |
Show |
Top
The GO tree — Biological processes
HELP
This is one of three sections showing Gene Ontology enrichment of the
current module: in this case for biological processes.
The graph shows the hierarchy of the GO categories, their enrichment
for the current module is color coded, and the blue number beside the
category is the minus log ten p-value of the enrichment. (Calculated
using the standard hypergeometric test.) The color of the arrows code
«is a» (cyan) and «part of» relationships.
The tree was built the following way. First all GO terms with more
significant enrichment p-value than 0.05 were collected. Then all
paths from these terms to the root node of the GO tree were included
too. If a GO term is included more than once in the tree, then the
green numbers show 1) the id of the node, this makes it easier to find
other appereances of the term, and 2) the number of appearences.
Note that the same GO category might show up on the graph many
times. This is because the GO was «straightened» for this
graph, i.e. if there are more paths from a GO term to the root node of
the tree, all of them are included. The green numbers
Move the mouse cursor over the terms to get their definition. Clicking
on them takes you to the corresponding Gene Ontology web page.
If you cannot see a graph here at all, that means that there were no
significantly enriched GO categories, at the 0.05 level.
— Click on the Help button again to close this help window.

Help |
Hide |
Top
Help |
Show |
Top
The GO tree — Cellular Components
HELP
This is one of three sections showing Gene Ontology enrichment of the
current module: in this case for cellular components.
The graph shows the hierarchy of the GO categories, their enrichment
for the current module is color coded, and the blue number beside the
category is the minus log ten p-value of the enrichment. (Calculated
using the standard hypergeometric test.) The color of the arrows code
«is a» (cyan) and «part of» relationships.
The tree was built the following way. First all GO terms with more
significant enrichment p-value than 0.05 were collected. Then all
paths from these terms to the root node of the GO tree were included
too. If a GO term is included more than once in the tree, then the
green numbers show 1) the id of the node, this makes it easier to find
other appereances of the term, and 2) the number of appearences.
Note that the same GO category might show up on the graph many
times. This is because the GO was «straightened» for this
graph, i.e. if there are more paths from a GO term to the root node of
the tree, all of them are included. The green numbers
Move the mouse cursor over the terms to get their definition. Clicking
on them takes you to the corresponding Gene Ontology web page.
If you cannot see a graph here at all, that means that there were no
significantly enriched GO categories, at the 0.05 level.
— Click on the Help button again to close this help window.
plasma membrane
The membrane surrounding a cell that separates the cell from its external environment. It consists of a phospholipid bilayer and associated proteins.
membrane
Double layer of lipid molecules that encloses all cells, and, in eukaryotes, many organelles; may be a single or double lipid bilayer; also includes associated proteins.
integral to membrane
Penetrating at least one phospholipid bilayer of a membrane. May also refer to the state of being buried in the bilayer with no exposure outside the bilayer. When used to describe a protein, indicates that all or part of the peptide sequence is embedded in the membrane.
integral to plasma membrane
Penetrating at least one phospholipid bilayer of a plasma membrane. May also refer to the state of being buried in the bilayer with no exposure outside the bilayer.
cellular_component
The part of a cell or its extracellular environment in which a gene product is located. A gene product may be located in one or more parts of a cell and its location may be as specific as a particular macromolecular complex, that is, a stable, persistent association of macromolecules that function together.
cell
The basic structural and functional unit of all organisms. Includes the plasma membrane and any external encapsulating structures such as the cell wall and cell envelope.
intrinsic to membrane
Located in a membrane such that some covalently attached portion of the gene product, for example part of a peptide sequence or some other covalently attached moiety such as a GPI anchor, spans or is embedded in one or both leaflets of the membrane.
intrinsic to plasma membrane
Located in the plasma membrane such that some covalently attached portion of the gene product, for example part of a peptide sequence or some other covalently attached moiety such as a GPI anchor, spans or is embedded in one or both leaflets of the membrane.
membrane part
Any constituent part of a membrane, a double layer of lipid molecules that encloses all cells, and, in eukaryotes, many organelles; may be a single or double lipid bilayer; also includes associated proteins.
plasma membrane part
Any constituent part of the plasma membrane, the membrane surrounding a cell that separates the cell from its external environment. It consists of a phospholipid bilayer and associated proteins.
cell part
Any constituent part of a cell, the basic structural and functional unit of all organisms.
all
This term is the most general term possible
cell part
Any constituent part of a cell, the basic structural and functional unit of all organisms.
membrane part
Any constituent part of a membrane, a double layer of lipid molecules that encloses all cells, and, in eukaryotes, many organelles; may be a single or double lipid bilayer; also includes associated proteins.
plasma membrane part
Any constituent part of the plasma membrane, the membrane surrounding a cell that separates the cell from its external environment. It consists of a phospholipid bilayer and associated proteins.
intrinsic to plasma membrane
Located in the plasma membrane such that some covalently attached portion of the gene product, for example part of a peptide sequence or some other covalently attached moiety such as a GPI anchor, spans or is embedded in one or both leaflets of the membrane.
integral to plasma membrane
Penetrating at least one phospholipid bilayer of a plasma membrane. May also refer to the state of being buried in the bilayer with no exposure outside the bilayer.
Help |
Hide |
Top
Help |
Show |
Top
The GO tree — Molecular Function
HELP
This is one of three sections showing Gene Ontology enrichment of the
current module: in this case for molecular function.
The graph shows the hierarchy of the GO categories, their enrichment
for the current module is color coded, and the blue number beside the
category is the minus log ten p-value of the enrichment. (Calculated
using the standard hypergeometric test.) The color of the arrows code
«is a» (cyan) and «part of» relationships.
The tree was built the following way. First all GO terms with more
significant enrichment p-value than 0.05 were collected. Then all
paths from these terms to the root node of the GO tree were included
too. If a GO term is included more than once in the tree, then the
green numbers show 1) the id of the node, this makes it easier to find
other appereances of the term, and 2) the number of appearences.
Note that the same GO category might show up on the graph many
times. This is because the GO was «straightened» for this
graph, i.e. if there are more paths from a GO term to the root node of
the tree, all of them are included. The green numbers
Move the mouse cursor over the terms to get their definition. Clicking
on them takes you to the corresponding Gene Ontology web page.
If you cannot see a graph here at all, that means that there were no
significantly enriched GO categories, at the 0.05 level.
— Click on the Help button again to close this help window.
molecular_function
Elemental activities, such as catalysis or binding, describing the actions of a gene product at the molecular level. A given gene product may exhibit one or more molecular functions.
signal transducer activity
Mediates the transfer of a signal from the outside to the inside of a cell by means other than the introduction of the signal molecule itself into the cell.
molecular transducer activity
The molecular function that accepts an input of one form and creates an output of a different form.
all
This term is the most general term possible
Help |
Hide |
Top
Help |
Show |
Top
GO BP test for over-representation
HELP
List of all enriched GO categories (biological processes), at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module annotated with the given GO term, just by chance.
- Count
is the number of genes in the module annotated with the given GO
term.
- Size is the total number of genes (in our universe)
annotated with the GO term.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
GO category.
Clicking on the GO identifiers takes you to the Gene Ontology web
pages.
— Click on the Help button again to close this help window.
| Id | Pvalue | ExpCount | Count | Size | Term |
| GO:0017157 | 1.670e-02 | 0.1247 | 3
FCER1G, SEPT5, SYT1 | 10 | regulation of exocytosis |
| GO:0006955 | 2.040e-02 | 3.679 | 12
C4A, CD70, CD79B, CD80, CYBB, DMBT1, EDA, FCER1G, HAMP, ITGAL, LILRA5, LILRB3 | 295 | immune response |
| GO:0050896 | 3.748e-02 | 16.84 | 30
ADORA1, ATM, C19orf40, C4A, CD70, CD79B, CD80, CHRNB2, CYBB, DMBT1, DUSP9, EDA, F11, FCER1G, HAMP, ITGAL, KRT8, LILRA5, LILRB3, MYO15A, NDP, PKLR, PMS2L2, RBM38, SH2D3A, SIGLEC1, STIM1, SYT1, TMPRSS6, TP53TG1 | 1350 | response to stimulus |
| GO:0005513 | 4.694e-02 | 0.04989 | 2
STIM1, SYT1 | 4 | detection of calcium ion |
Help |
Hide |
Top
Help |
Show |
Top
GO CC test for over-representation
HELP
List of all enriched GO categories (cellular components), at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module annotated with the given GO term, just by chance.
- Count
is the number of genes in the module annotated with the given GO
term.
- Size is the total number of genes (in our universe)
annotated with the GO term.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
GO category.
Clicking on the GO identifiers takes you to the Gene Ontology web
pages.
— Click on the Help button again to close this help window.
| Id | Pvalue | ExpCount | Count | Size | Term |
| GO:0005886 | 3.679e-04 | 17.66 | 36
ABCA7, ADORA1, ADRA1D, ALPPL2, AP1G2, APP, BCAM, CD70, CD79B, CD80, CHRNB2, CNNM3, CYBB, EDA, EPN1, FCER1G, FLRT3, GPR144, GPR32, GRM1, HPN, ITGAL, KRT8, LILRB3, OPRL1, PARD6A, SEPT5, SIGLEC1, SLC5A5, SLC6A11, SLCO2A1, SORBS1, STIM1, SYT1, TMPRSS6, TNFRSF8 | 1443 | plasma membrane |
| GO:0005887 | 1.221e-03 | 6.717 | 19
ADORA1, ADRA1D, APP, BCAM, CD70, CD79B, CHRNB2, CYBB, FCER1G, FLRT3, GPR32, GRM1, HPN, ITGAL, LILRB3, OPRL1, SLC6A11, SLCO2A1, STIM1 | 549 | integral to plasma membrane |
| GO:0031226 | 1.362e-03 | 6.778 | 19
ADORA1, ADRA1D, APP, BCAM, CD70, CD79B, CHRNB2, CYBB, FCER1G, FLRT3, GPR32, GRM1, HPN, ITGAL, LILRB3, OPRL1, SLC6A11, SLCO2A1, STIM1 | 554 | intrinsic to plasma membrane |
| GO:0044459 | 3.552e-03 | 10.71 | 24
ABCA7, ADORA1, ADRA1D, APP, BCAM, CD70, CD79B, CHRNB2, CYBB, EPN1, FCER1G, FLRT3, GPR32, GRM1, HPN, ITGAL, LILRB3, OPRL1, PARD6A, SLC6A11, SLCO2A1, SORBS1, STIM1, SYT1 | 875 | plasma membrane part |
| GO:0030666 | 4.753e-02 | 0.07341 | 2
DMBT1, SYT1 | 6 | endocytic vesicle membrane |
Help |
Hide |
Top
Help |
Show |
Top
GO MF test for over-representation
HELP
List of all enriched GO categories (molecular function), at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module annotated with the given GO term, just by chance.
- Count
is the number of genes in the module annotated with the given GO
term.
- Size is the total number of genes (in our universe)
annotated with the GO term.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
GO category.
Clicking on the GO identifiers takes you to the Gene Ontology web
pages.
— Click on the Help button again to close this help window.
| Id | Pvalue | ExpCount | Count | Size | Term |
| GO:0004871 | 6.947e-03 | 10.22 | 24
ADORA1, ADRA1D, BCAM, BRAF, CC2D1A, CD79B, CD80, CHRNB2, DMBT1, FCER1G, FLRT3, GPR144, GPR32, GRM1, HPN, ITGAL, LILRA5, LILRB3, OPRL1, PLXNB3, SH2D3A, TNFRSF8, TNK1, TP53TG1 | 798 | signal transducer activity |
| GO:0060089 | 6.947e-03 | 10.22 | 24
ADORA1, ADRA1D, BCAM, BRAF, CC2D1A, CD79B, CD80, CHRNB2, DMBT1, FCER1G, FLRT3, GPR144, GPR32, GRM1, HPN, ITGAL, LILRA5, LILRB3, OPRL1, PLXNB3, SH2D3A, TNFRSF8, TNK1, TP53TG1 | 798 | molecular transducer activity |
| GO:0004888 | 1.040e-02 | 4.277 | 14
ADORA1, ADRA1D, BCAM, CD79B, CHRNB2, DMBT1, FCER1G, GPR144, GPR32, GRM1, HPN, LILRB3, OPRL1, TNFRSF8 | 334 | transmembrane receptor activity |
| GO:0004872 | 1.404e-02 | 6.824 | 18
ADORA1, ADRA1D, BCAM, CD79B, CD80, CHRNB2, DMBT1, FCER1G, GPR144, GPR32, GRM1, HPN, ITGAL, LILRA5, LILRB3, OPRL1, PLXNB3, TNFRSF8 | 533 | receptor activity |
Help |
Hide |
Top
Help |
Show |
Top
KEGG Pathway test for over-representation
HELP
List of all enriched KEGG pathways, at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module annotated with the given KEGG pathway, just by chance.
- Count
is the number of genes in the module annotated with the given KEGG
pathway.
- Size is the total number of genes (in our universe)
annotated with the KEGG pathway.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
KEGG pathway.
Clicking on the KEGG identifiers takes you to the KEGG web site.
— Click on the Help button again to close this help window.
Help |
Hide |
Top
Help |
Show |
Top
miRNA test for over-representation
HELP
List of all enriched miRNA families, at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module regulated by the given miRNA family, just by chance.
- Count
is the number of genes in the module regulated by the given miRNA
family.
- Size is the total number of genes (in our universe)
regulated with the given miRNA family.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
miRNA family.
The miRNA regulation data was taken from the TargetScan database.
(Only the conserved sites were used for the current analysis.)
Clicking on the miRNA names takes you to the TargetScan web site.
— Click on the Help button again to close this help window.
Help |
Hide |
Top
Help |
Show |
Top
Chromosome test for over-representation
HELP
List of all enriched Chromosomes, at the 0.05
p-value level.
The columns:
- ExpCount is the expected number of genes in the
module on the given chromosome, just by chance.
- Count
is the number of genes in the module on the given chromosome.
- Size is the total number of genes (in our universe)
on the given chromosome.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
chromosome.
— Click on the Help button again to close this help window.
| Id | Pvalue | ExpCount | Count | Size |
| 19 | 4.547e-04 | 7.239 | 23
ABCA7, BCAM, C19orf40, CC2D1A, CD70, EPN1, EPS8L1, GPR32, HAMP, HPN, ISOC2, LILRA5, LILRB3, LOC80054, MEF2B, NOVA2, PNMAL1, SH2D3A, SLC5A5, STXBP2, TULP2, ZNF702P, ZNF814 | 580 |
HELP
A list of all genes in the current module, in alphabetical order. The
size of the text corresponds to the gene scores.
Note that some gene symbols may show up more than once, if many
probes match the same Entrez gene.
Genes with no Entrez mapping are given separately, with their
Affymetrics probe ID.
— Click on the Help button again to close this help window.
Entrez genes
ABCA7ATP-binding cassette, sub-family A (ABC1), member 7 (219577_s_at), score: 0.91
ADAMTS7ADAM metallopeptidase with thrombospondin type 1 motif, 7 (220705_s_at), score: 0.63
ADORA1adenosine A1 receptor (216220_s_at), score: 0.72
ADRA1Dadrenergic, alpha-1D-, receptor (210961_s_at), score: 0.62
ALDH1L1aldehyde dehydrogenase 1 family, member L1 (215798_at), score: 0.6
ALDH3A1aldehyde dehydrogenase 3 family, memberA1 (205623_at), score: 0.61
ALPPL2alkaline phosphatase, placental-like 2 (216377_x_at), score: 0.76
AP1G2adaptor-related protein complex 1, gamma 2 subunit (201613_s_at), score: 0.64
APPamyloid beta (A4) precursor protein (214953_s_at), score: 0.86
ASPHD1aspartate beta-hydroxylase domain containing 1 (214993_at), score: 0.71
ATMataxia telangiectasia mutated (210858_x_at), score: 0.61
BCAMbasal cell adhesion molecule (Lutheran blood group) (40093_at), score: 0.77
BRAFv-raf murine sarcoma viral oncogene homolog B1 (206044_s_at), score: -0.72
C10orf84chromosome 10 open reading frame 84 (218390_s_at), score: -0.62
C19orf40chromosome 19 open reading frame 40 (214816_x_at), score: 0.63
C1orf69chromosome 1 open reading frame 69 (215490_at), score: 0.63
C2orf37chromosome 2 open reading frame 37 (220172_at), score: -0.71
C2orf72chromosome 2 open reading frame 72 (213143_at), score: 0.65
C4Acomplement component 4A (Rodgers blood group) (214428_x_at), score: 0.69
CC2D1Acoiled-coil and C2 domain containing 1A (58994_at), score: 0.64
CCDC33coiled-coil domain containing 33 (220908_at), score: 0.78
CCDC40coiled-coil domain containing 40 (220592_at), score: 0.98
CD70CD70 molecule (206508_at), score: 0.63
CD79BCD79b molecule, immunoglobulin-associated beta (205297_s_at), score: 0.83
CD80CD80 molecule (207176_s_at), score: -0.65
CHRNB2cholinergic receptor, nicotinic, beta 2 (neuronal) (206635_at), score: 0.69
CNNM3cyclin M3 (220739_s_at), score: -0.74
CYBBcytochrome b-245, beta polypeptide (203923_s_at), score: 0.7
CYTH4cytohesin 4 (219183_s_at), score: 0.63
DMBT1deleted in malignant brain tumors 1 (208250_s_at), score: 0.82
DSPPdentin sialophosphoprotein (221681_s_at), score: 0.84
DUSP9dual specificity phosphatase 9 (205777_at), score: 0.61
EDAectodysplasin A (211130_x_at), score: 0.92
EPN1epsin 1 (221141_x_at), score: 0.63
EPS8L1EPS8-like 1 (218778_x_at), score: 0.66
F11coagulation factor XI (206610_s_at), score: 0.66
FBXO2F-box protein 2 (219305_x_at), score: 0.6
FCER1GFc fragment of IgE, high affinity I, receptor for; gamma polypeptide (204232_at), score: 0.64
FKBP10FK506 binding protein 10, 65 kDa (219249_s_at), score: 1
FLCNfolliculin (215645_at), score: 0.66
FLRT3fibronectin leucine rich transmembrane protein 3 (219250_s_at), score: -0.72
GANgigaxonin (220124_at), score: -0.67
GBA3glucosidase, beta, acid 3 (cytosolic) (219954_s_at), score: 0.67
GGT1gamma-glutamyltransferase 1 (209919_x_at), score: 0.64
GNL3LPguanine nucleotide binding protein-like 3 (nucleolar)-like pseudogene (220716_at), score: 0.65
GPR144G protein-coupled receptor 144 (216289_at), score: 0.87
GPR32G protein-coupled receptor 32 (221469_at), score: 0.66
GRM1glutamate receptor, metabotropic 1 (210939_s_at), score: 0.8
HAB1B1 for mucin (215778_x_at), score: 0.86
HAMPhepcidin antimicrobial peptide (220491_at), score: 0.7
HPNhepsin (204934_s_at), score: 0.6
IFT140intraflagellar transport 140 homolog (Chlamydomonas) (204792_s_at), score: 0.72
INAinternexin neuronal intermediate filament protein, alpha (204465_s_at), score: -0.66
ISOC2isochorismatase domain containing 2 (218893_at), score: 0.6
ITGALintegrin, alpha L (antigen CD11A (p180), lymphocyte function-associated antigen 1; alpha polypeptide) (213475_s_at), score: 0.91
KIF26Bkinesin family member 26B (220002_at), score: 0.63
KRT8keratin 8 (209008_x_at), score: 0.67
KRT8P12keratin 8 pseudogene 12 (222060_at), score: 0.65
LILRA5leukocyte immunoglobulin-like receptor, subfamily A (with TM domain), member 5 (215838_at), score: 0.87
LILRB3leukocyte immunoglobulin-like receptor, subfamily B (with TM and ITIM domains), member 3 (211133_x_at), score: 0.81
LOC100133748similar to GTF2IRD2 protein (215569_at), score: 0.62
LOC149478hypothetical protein LOC149478 (215462_at), score: 0.68
LOC149501similar to keratin 8 (216821_at), score: 0.66
LOC80054hypothetical LOC80054 (220465_at), score: 0.6
MAPK8IP1mitogen-activated protein kinase 8 interacting protein 1 (213013_at), score: 0.77
MDM2Mdm2 p53 binding protein homolog (mouse) (205386_s_at), score: -0.75
MEF2Bmyocyte enhancer factor 2B (209926_at), score: 0.65
MOCS1molybdenum cofactor synthesis 1 (211673_s_at), score: 0.82
MUC5ACmucin 5AC, oligomeric mucus/gel-forming (217182_at), score: 0.76
MYO15Amyosin XVA (220288_at), score: 0.61
NDPNorrie disease (pseudoglioma) (206022_at), score: -0.72
NOVA2neuro-oncological ventral antigen 2 (206477_s_at), score: 0.77
NPEPL1aminopeptidase-like 1 (89476_r_at), score: 0.65
OPRL1opiate receptor-like 1 (206564_at), score: 0.71
PARD6Apar-6 partitioning defective 6 homolog alpha (C. elegans) (205245_at), score: 0.61
PHC1polyhomeotic homolog 1 (Drosophila) (218338_at), score: -0.66
PHF2PHD finger protein 2 (212726_at), score: -0.84
PIN1Lpeptidylprolyl cis/trans isomerase, NIMA-interacting 1-like (pseudogene) (207582_at), score: 0.6
PIPOXpipecolic acid oxidase (221605_s_at), score: 0.69
PKLRpyruvate kinase, liver and RBC (222078_at), score: 0.89
PLXNB3plexin B3 (205957_at), score: 0.6
PMS2L2postmeiotic segregation increased 2-like 2 pseudogene (215410_at), score: 0.81
PNMAL1PNMA-like 1 (218824_at), score: -0.73
POM121L2POM121 membrane glycoprotein-like 2 (rat) (216582_at), score: 0.97
PRLHprolactin releasing hormone (221443_x_at), score: 0.74
PTPN6protein tyrosine phosphatase, non-receptor type 6 (206687_s_at), score: 0.76
RBM12BRNA binding motif protein 12B (51228_at), score: -0.87
RBM38RNA binding motif protein 38 (212430_at), score: 0.93
RNF121ring finger protein 121 (219021_at), score: 0.87
RPL18AP6ribosomal protein L18a pseudogene 6 (216383_at), score: 0.67
SCLYselenocysteine lyase (221575_at), score: -0.67
SEPT5septin 5 (209767_s_at), score: 0.69
SH2D3ASH2 domain containing 3A (222169_x_at), score: 0.69
SIGLEC1sialic acid binding Ig-like lectin 1, sialoadhesin (44673_at), score: 0.62
SLC30A4solute carrier family 30 (zinc transporter), member 4 (207362_at), score: -0.83
SLC5A5solute carrier family 5 (sodium iodide symporter), member 5 (211123_at), score: 0.69
SLC6A11solute carrier family 6 (neurotransmitter transporter, GABA), member 11 (207048_at), score: 0.72
SLCO2A1solute carrier organic anion transporter family, member 2A1 (204368_at), score: 0.62
SORBS1sorbin and SH3 domain containing 1 (218087_s_at), score: 0.61
SPATA1spermatogenesis associated 1 (221057_at), score: 0.74
SSX3synovial sarcoma, X breakpoint 3 (211731_x_at), score: 0.6
ST8SIA3ST8 alpha-N-acetyl-neuraminide alpha-2,8-sialyltransferase 3 (208064_s_at), score: 0.8
STIM1stromal interaction molecule 1 (202764_at), score: -0.69
STXBP2syntaxin binding protein 2 (209367_at), score: 0.65
SYT1synaptotagmin I (203999_at), score: -0.7
TAF15TAF15 RNA polymerase II, TATA box binding protein (TBP)-associated factor, 68kDa (202840_at), score: 0.83
TAL1T-cell acute lymphocytic leukemia 1 (206283_s_at), score: 0.63
TMPRSS6transmembrane protease, serine 6 (214955_at), score: 0.92
TMSB4Ythymosin beta 4, Y-linked (206769_at), score: 0.7
TNFRSF8tumor necrosis factor receptor superfamily, member 8 (206729_at), score: 0.77
TNK1tyrosine kinase, non-receptor, 1 (217149_x_at), score: 0.66
TP53TG1TP53 target 1 (non-protein coding) (210241_s_at), score: 0.66
TULP2tubby like protein 2 (206733_at), score: 0.88
YPEL1yippee-like 1 (Drosophila) (206063_x_at), score: 0.7
ZNF192zinc finger protein 192 (206579_at), score: -0.75
ZNF214zinc finger protein 214 (220497_at), score: -0.72
ZNF702Pzinc finger protein 702 pseudogene (206557_at), score: -0.66
ZNF814zinc finger protein 814 (60794_f_at), score: -0.65
Non-Entrez genes
Unknown, score:
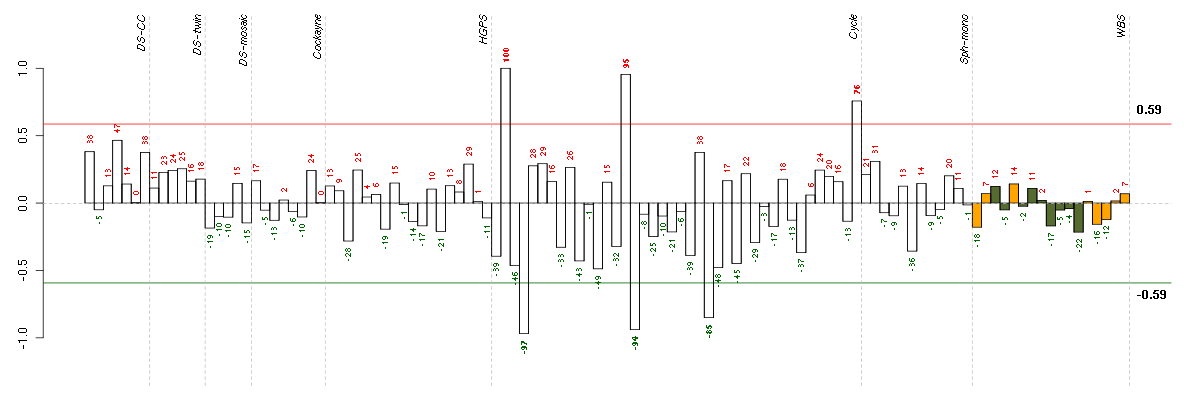
HELP
Conditions in the module, given in the same order as on the expression
plot above. Red color means over-expression, green under-expression in
the given condition.
The barplot below shows the condition (sample) scores. A separate bar
is shown for each sample, its height is the corresponding score of the
sample in the module. The red and green numbers on the bars are the
sample scores expressed in percents, i.e. 100% is 1.0.
The red and green lines show the module thresholds, samples above
the red line and below the green line are included in the module.
The different experiments that were part of the study, are separated
by dashed vertical lines.
— Click on the Help button again to close this help window.
| Id | sample | Experiment | ExpName | Array | Syndrome | Cell.line |
| E-TABM-263-raw-cel-1515485711.cel | 4 | 6 | Cycle | hgu133a2 | none | Cycle 1 |
| E-TABM-263-raw-cel-1515485951.cel | 16 | 6 | Cycle | hgu133a2 | none | Cycle 1 |
| E-TABM-263-raw-cel-1515486111.cel | 24 | 6 | Cycle | hgu133a2 | none | Cycle 1 |
| E-TABM-263-raw-cel-1515486431.cel | 40 | 6 | Cycle | hgu133a2 | none | Cycle 1 |
| E-TABM-263-raw-cel-1515485931.cel | 15 | 6 | Cycle | hgu133a2 | none | Cycle 1 |
| E-TABM-263-raw-cel-1515485671.cel | 2 | 6 | Cycle | hgu133a2 | none | Cycle 1 |



© 2008-2010 Computational Biology Group, Department of Medical Genetics,
University of Lausanne, Switzerland
