Previous module |
Next module
Module #605, TG: 2.8, TC: 2, 126 probes, 126 Entrez genes, 4 conditions


HELP
The image plot shows the color-coded level of gene expression, for the
genes and conditions in a given transcription module. The genes are on
the horizontal, the conditions on the vertical axis.
The genes are ordered according to their ISA gene scores, similarly
the conditions are ordered according to their condition scores. The
score of a gene means the «degree of inclusion» in
the module: a high score gene is essential in the module.
Condition scores can also be negative, that means that the genes of
the module are all down-regulated in the condition. Here the absolute
value of the score gives the «degree of inclusion».
The plots above and beside the expression matrix show the gene scores
and condition scores, respectively.
Note that the plot is interactive, you can see the name of the gene
and condition under the mouse cursor.
The expression matrix was normalized to have mean zero and standard
deviation one for every gene separately across all conditions
(i.e. not just for the conditions in the module).
— Click on the Help button again to close this help window.

Under-expression is coded with green,
over-expression with red color.
Help |
Hide |
Top
Help |
Show |
Top
The GO tree — Biological processes
HELP
This is one of three sections showing Gene Ontology enrichment of the
current module: in this case for biological processes.
The graph shows the hierarchy of the GO categories, their enrichment
for the current module is color coded, and the blue number beside the
category is the minus log ten p-value of the enrichment. (Calculated
using the standard hypergeometric test.) The color of the arrows code
«is a» (cyan) and «part of» relationships.
The tree was built the following way. First all GO terms with more
significant enrichment p-value than 0.05 were collected. Then all
paths from these terms to the root node of the GO tree were included
too. If a GO term is included more than once in the tree, then the
green numbers show 1) the id of the node, this makes it easier to find
other appereances of the term, and 2) the number of appearences.
Note that the same GO category might show up on the graph many
times. This is because the GO was «straightened» for this
graph, i.e. if there are more paths from a GO term to the root node of
the tree, all of them are included. The green numbers
Move the mouse cursor over the terms to get their definition. Clicking
on them takes you to the corresponding Gene Ontology web page.
If you cannot see a graph here at all, that means that there were no
significantly enriched GO categories, at the 0.05 level.
— Click on the Help button again to close this help window.

defense response
Reactions, triggered in response to the presence of a foreign body or the occurrence of an injury, which result in restriction of damage to the organism attacked or prevention/recovery from the infection caused by the attack.
response to stress
A change in state or activity of a cell or an organism (in terms of movement, secretion, enzyme production, gene expression, etc.) as a result of a disturbance in organismal or cellular homeostasis, usually, but not necessarily, exogenous (e.g. temperature, humidity, ionizing radiation).
biological_process
Any process specifically pertinent to the functioning of integrated living units: cells, tissues, organs, and organisms. A process is a collection of molecular events with a defined beginning and end.
response to stimulus
A change in state or activity of a cell or an organism (in terms of movement, secretion, enzyme production, gene expression, etc.) as a result of a stimulus.
all
This term is the most general term possible
Help |
Hide |
Top
Help |
Show |
Top
The GO tree — Cellular Components
HELP
This is one of three sections showing Gene Ontology enrichment of the
current module: in this case for cellular components.
The graph shows the hierarchy of the GO categories, their enrichment
for the current module is color coded, and the blue number beside the
category is the minus log ten p-value of the enrichment. (Calculated
using the standard hypergeometric test.) The color of the arrows code
«is a» (cyan) and «part of» relationships.
The tree was built the following way. First all GO terms with more
significant enrichment p-value than 0.05 were collected. Then all
paths from these terms to the root node of the GO tree were included
too. If a GO term is included more than once in the tree, then the
green numbers show 1) the id of the node, this makes it easier to find
other appereances of the term, and 2) the number of appearences.
Note that the same GO category might show up on the graph many
times. This is because the GO was «straightened» for this
graph, i.e. if there are more paths from a GO term to the root node of
the tree, all of them are included. The green numbers
Move the mouse cursor over the terms to get their definition. Clicking
on them takes you to the corresponding Gene Ontology web page.
If you cannot see a graph here at all, that means that there were no
significantly enriched GO categories, at the 0.05 level.
— Click on the Help button again to close this help window.
Help |
Hide |
Top
Help |
Show |
Top
The GO tree — Molecular Function
HELP
This is one of three sections showing Gene Ontology enrichment of the
current module: in this case for molecular function.
The graph shows the hierarchy of the GO categories, their enrichment
for the current module is color coded, and the blue number beside the
category is the minus log ten p-value of the enrichment. (Calculated
using the standard hypergeometric test.) The color of the arrows code
«is a» (cyan) and «part of» relationships.
The tree was built the following way. First all GO terms with more
significant enrichment p-value than 0.05 were collected. Then all
paths from these terms to the root node of the GO tree were included
too. If a GO term is included more than once in the tree, then the
green numbers show 1) the id of the node, this makes it easier to find
other appereances of the term, and 2) the number of appearences.
Note that the same GO category might show up on the graph many
times. This is because the GO was «straightened» for this
graph, i.e. if there are more paths from a GO term to the root node of
the tree, all of them are included. The green numbers
Move the mouse cursor over the terms to get their definition. Clicking
on them takes you to the corresponding Gene Ontology web page.
If you cannot see a graph here at all, that means that there were no
significantly enriched GO categories, at the 0.05 level.
— Click on the Help button again to close this help window.
Help |
Hide |
Top
Help |
Show |
Top
GO BP test for over-representation
HELP
List of all enriched GO categories (biological processes), at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module annotated with the given GO term, just by chance.
- Count
is the number of genes in the module annotated with the given GO
term.
- Size is the total number of genes (in our universe)
annotated with the GO term.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
GO category.
Clicking on the GO identifiers takes you to the Gene Ontology web
pages.
— Click on the Help button again to close this help window.
| Id | Pvalue | ExpCount | Count | Size | Term |
| GO:0006952 | 6.243e-03 | 3.136 | 12
ADORA1, CNR2, CYBB, GATA3, IL18R1, ITGAL, LILRB3, LY75, PLA2G7, SAA4, SARM1, SIGLEC1 | 263 | defense response |
| GO:0006954 | 2.911e-02 | 1.824 | 8
ADORA1, CNR2, CYBB, ITGAL, LY75, PLA2G7, SAA4, SIGLEC1 | 153 | inflammatory response |
| GO:0006955 | 3.988e-02 | 3.518 | 11
CNR2, CYBB, EDA, HLA-DMB, HLA-DQB1, IL18R1, ITGAL, LILRA5, LILRB3, LY75, SARM1 | 295 | immune response |
| GO:0042089 | 4.411e-02 | 0.4293 | 4
ASB1, INHA, PCSK5, TNFRSF8 | 36 | cytokine biosynthetic process |
| GO:0042107 | 4.745e-02 | 0.4412 | 4
ASB1, INHA, PCSK5, TNFRSF8 | 37 | cytokine metabolic process |
Help |
Hide |
Top
Help |
Show |
Top
GO CC test for over-representation
HELP
List of all enriched GO categories (cellular components), at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module annotated with the given GO term, just by chance.
- Count
is the number of genes in the module annotated with the given GO
term.
- Size is the total number of genes (in our universe)
annotated with the GO term.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
GO category.
Clicking on the GO identifiers takes you to the Gene Ontology web
pages.
— Click on the Help button again to close this help window.
Help |
Hide |
Top
Help |
Show |
Top
GO MF test for over-representation
HELP
List of all enriched GO categories (molecular function), at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module annotated with the given GO term, just by chance.
- Count
is the number of genes in the module annotated with the given GO
term.
- Size is the total number of genes (in our universe)
annotated with the GO term.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
GO category.
Clicking on the GO identifiers takes you to the Gene Ontology web
pages.
— Click on the Help button again to close this help window.
Help |
Hide |
Top
Help |
Show |
Top
KEGG Pathway test for over-representation
HELP
List of all enriched KEGG pathways, at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module annotated with the given KEGG pathway, just by chance.
- Count
is the number of genes in the module annotated with the given KEGG
pathway.
- Size is the total number of genes (in our universe)
annotated with the KEGG pathway.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
KEGG pathway.
Clicking on the KEGG identifiers takes you to the KEGG web site.
— Click on the Help button again to close this help window.
Help |
Hide |
Top
Help |
Show |
Top
miRNA test for over-representation
HELP
List of all enriched miRNA families, at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module regulated by the given miRNA family, just by chance.
- Count
is the number of genes in the module regulated by the given miRNA
family.
- Size is the total number of genes (in our universe)
regulated with the given miRNA family.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
miRNA family.
The miRNA regulation data was taken from the TargetScan database.
(Only the conserved sites were used for the current analysis.)
Clicking on the miRNA names takes you to the TargetScan web site.
— Click on the Help button again to close this help window.
Help |
Hide |
Top
Help |
Show |
Top
Chromosome test for over-representation
HELP
List of all enriched Chromosomes, at the 0.05
p-value level.
The columns:
- ExpCount is the expected number of genes in the
module on the given chromosome, just by chance.
- Count
is the number of genes in the module on the given chromosome.
- Size is the total number of genes (in our universe)
on the given chromosome.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
chromosome.
— Click on the Help button again to close this help window.
HELP
A list of all genes in the current module, in alphabetical order. The
size of the text corresponds to the gene scores.
Note that some gene symbols may show up more than once, if many
probes match the same Entrez gene.
Genes with no Entrez mapping are given separately, with their
Affymetrics probe ID.
— Click on the Help button again to close this help window.
Entrez genes
ACADSacyl-Coenzyme A dehydrogenase, C-2 to C-3 short chain (202366_at), score: -0.5
ACTN3actinin, alpha 3 (206891_at), score: -0.54
ADORA1adenosine A1 receptor (216220_s_at), score: -0.54
AFTPHaftiphilin (217939_s_at), score: -0.49
AGAP2ArfGAP with GTPase domain, ankyrin repeat and PH domain 2 (215080_s_at), score: -0.47
ANKRD36ankyrin repeat domain 36 (214723_x_at), score: 0.57
APPamyloid beta (A4) precursor protein (214953_s_at), score: -0.57
ASB1ankyrin repeat and SOCS box-containing 1 (212819_at), score: 0.58
ATP6V0E1ATPase, H+ transporting, lysosomal 9kDa, V0 subunit e1 (214244_s_at), score: -0.55
ATPAF2ATP synthase mitochondrial F1 complex assembly factor 2 (213057_at), score: -0.53
B3GALT4UDP-Gal:betaGlcNAc beta 1,3-galactosyltransferase, polypeptide 4 (210205_at), score: -0.67
BRD1bromodomain containing 1 (204520_x_at), score: 0.61
C10orf118chromosome 10 open reading frame 118 (219844_at), score: 0.54
C2orf67chromosome 2 open reading frame 67 (215046_at), score: -0.53
CCDC40coiled-coil domain containing 40 (220592_at), score: -0.54
CCRN4LCCR4 carbon catabolite repression 4-like (S. cerevisiae) (220671_at), score: -0.53
CD2CD2 molecule (205831_at), score: -0.55
CD53CD53 molecule (203416_at), score: -0.55
CHRNB2cholinergic receptor, nicotinic, beta 2 (neuronal) (206635_at), score: -0.61
CNNM3cyclin M3 (220739_s_at), score: 0.67
CNOT3CCR4-NOT transcription complex, subunit 3 (203239_s_at), score: 0.47
CNR2cannabinoid receptor 2 (macrophage) (206586_at), score: -0.59
CYBBcytochrome b-245, beta polypeptide (203923_s_at), score: -0.55
DBPD site of albumin promoter (albumin D-box) binding protein (40273_at), score: 0.58
DENND4BDENN/MADD domain containing 4B (202860_at), score: 0.64
DHX35DEAH (Asp-Glu-Ala-His) box polypeptide 35 (218579_s_at), score: 0.52
DUSP9dual specificity phosphatase 9 (205777_at), score: -0.48
EDAectodysplasin A (211130_x_at), score: -0.49
EPORerythropoietin receptor (215054_at), score: -0.49
FBRSfibrosin (218255_s_at), score: -0.64
FGF4fibroblast growth factor 4 (206783_at), score: -0.52
FKBP10FK506 binding protein 10, 65 kDa (219249_s_at), score: -0.69
FLCNfolliculin (215645_at), score: -0.64
FOXK2forkhead box K2 (203064_s_at), score: 0.62
FOXN3forkhead box N3 (218031_s_at), score: 0.57
FRAT2frequently rearranged in advanced T-cell lymphomas 2 (209864_at), score: 0.65
FUT2fucosyltransferase 2 (secretor status included) (210608_s_at), score: -0.68
GATA3GATA binding protein 3 (209604_s_at), score: -0.48
GPATCH4G patch domain containing 4 (220596_at), score: -0.53
HAB1B1 for mucin (215778_x_at), score: -0.6
HHIPL2HHIP-like 2 (220283_at), score: -0.53
HIST1H2ALhistone cluster 1, H2al (214554_at), score: 0.51
HLA-DMBmajor histocompatibility complex, class II, DM beta (203932_at), score: -0.78
HLA-DQB1major histocompatibility complex, class II, DQ beta 1 (211654_x_at), score: -0.65
HUNKhormonally up-regulated Neu-associated kinase (219535_at), score: -0.49
IL18R1interleukin 18 receptor 1 (206618_at), score: 0.62
INAinternexin neuronal intermediate filament protein, alpha (204465_s_at), score: 0.54
INHAinhibin, alpha (210141_s_at), score: -0.5
IRAK4interleukin-1 receptor-associated kinase 4 (219618_at), score: 0.52
IRF2interferon regulatory factor 2 (203275_at), score: 0.51
ISOC2isochorismatase domain containing 2 (218893_at), score: -0.49
ITGALintegrin, alpha L (antigen CD11A (p180), lymphocyte function-associated antigen 1; alpha polypeptide) (213475_s_at), score: -0.68
KCNN2potassium intermediate/small conductance calcium-activated channel, subfamily N, member 2 (220116_at), score: -0.49
KIAA1324KIAA1324 (221874_at), score: 0.5
KRT86keratin 86 (215189_at), score: -0.66
KRT9keratin 9 (208188_at), score: -0.56
LILRA5leukocyte immunoglobulin-like receptor, subfamily A (with TM domain), member 5 (215838_at), score: -0.75
LILRB3leukocyte immunoglobulin-like receptor, subfamily B (with TM and ITIM domains), member 3 (211133_x_at), score: -0.49
LLGL2lethal giant larvae homolog 2 (Drosophila) (203713_s_at), score: -0.6
LOC100128223hypothetical protein LOC100128223 (221264_s_at), score: 0.64
LOC100129500hypothetical protein LOC100129500 (212884_x_at), score: -0.47
LOC128192similar to peptidyl-Pro cis trans isomerase (217346_at), score: -0.58
LOC80054hypothetical LOC80054 (220465_at), score: -0.49
LY75lymphocyte antigen 75 (205668_at), score: 0.71
MAGI1membrane associated guanylate kinase, WW and PDZ domain containing 1 (206144_at), score: 0.64
MAST4microtubule associated serine/threonine kinase family member 4 (40016_g_at), score: 0.51
MUC13mucin 13, cell surface associated (218687_s_at), score: -0.49
MYL4myosin, light chain 4, alkali; atrial, embryonic (210088_x_at), score: -0.51
NCRNA00093non-protein coding RNA 93 (210723_x_at), score: -0.5
NUCKS1nuclear casein kinase and cyclin-dependent kinase substrate 1 (217802_s_at), score: -0.48
NUDT13nudix (nucleoside diphosphate linked moiety X)-type motif 13 (214136_at), score: -0.49
PCSK5proprotein convertase subtilisin/kexin type 5 (213652_at), score: 0.66
PDCphosducin (211496_s_at), score: 0.53
PGCprogastricsin (pepsinogen C) (205261_at), score: -0.58
PKLRpyruvate kinase, liver and RBC (222078_at), score: -0.48
PKNOX2PBX/knotted 1 homeobox 2 (63305_at), score: 0.53
PLA2G7phospholipase A2, group VII (platelet-activating factor acetylhydrolase, plasma) (206214_at), score: -0.59
PMS2PMS2 postmeiotic segregation increased 2 (S. cerevisiae) (209805_at), score: -0.52
POLR3Gpolymerase (RNA) III (DNA directed) polypeptide G (32kD) (206653_at), score: 0.52
POM121L2POM121 membrane glycoprotein-like 2 (rat) (216582_at), score: -0.63
PPOXprotoporphyrinogen oxidase (204788_s_at), score: -0.47
PRAMEF11PRAME family member 11 (217365_at), score: -0.76
PRKCBprotein kinase C, beta (209685_s_at), score: -0.53
PRKG2protein kinase, cGMP-dependent, type II (207505_at), score: 0.53
PRLHprolactin releasing hormone (221443_x_at), score: -0.6
PTCD2pentatricopeptide repeat domain 2 (219658_at), score: 0.62
PTPN6protein tyrosine phosphatase, non-receptor type 6 (206687_s_at), score: -0.49
PYHIN1pyrin and HIN domain family, member 1 (216748_at), score: -0.52
RBM12BRNA binding motif protein 12B (51228_at), score: 0.51
RIMS2regulating synaptic membrane exocytosis 2 (215478_at), score: -0.51
RPL18AP6ribosomal protein L18a pseudogene 6 (216383_at), score: -0.5
S100A14S100 calcium binding protein A14 (218677_at), score: -0.54
SAA4serum amyloid A4, constitutive (207096_at), score: -0.64
SARM1sterile alpha and TIR motif containing 1 (213259_s_at), score: -0.62
SCN10Asodium channel, voltage-gated, type X, alpha subunit (208578_at), score: 0.57
SEPT5septin 5 (209767_s_at), score: -0.58
SF1splicing factor 1 (208313_s_at), score: 0.5
SHPKsedoheptulokinase (219713_at), score: -0.52
SIGLEC1sialic acid binding Ig-like lectin 1, sialoadhesin (44673_at), score: -0.49
SIN3BSIN3 homolog B, transcription regulator (yeast) (209352_s_at), score: 0.56
SLC10A1solute carrier family 10 (sodium/bile acid cotransporter family), member 1 (207185_at), score: -0.56
SLC30A4solute carrier family 30 (zinc transporter), member 4 (207362_at), score: 0.58
SLC6A11solute carrier family 6 (neurotransmitter transporter, GABA), member 11 (207048_at), score: -0.6
SLC9A7solute carrier family 9 (sodium/hydrogen exchanger), member 7 (214860_at), score: 0.6
SMA4glucuronidase, beta pseudogene (215599_at), score: 0.58
SNX27sorting nexin family member 27 (221006_s_at), score: 0.55
SPAG8sperm associated antigen 8 (206816_s_at), score: -0.65
SPATA1spermatogenesis associated 1 (221057_at), score: -0.51
TAF15TAF15 RNA polymerase II, TATA box binding protein (TBP)-associated factor, 68kDa (202840_at), score: -0.59
TBX10T-box 10 (207689_at), score: -0.68
TCP10t-complex 10 homolog (mouse) (207503_at), score: -0.7
TMCC2transmembrane and coiled-coil domain family 2 (213096_at), score: -0.7
TMPRSS6transmembrane protease, serine 6 (214955_at), score: -0.53
TMSB4Ythymosin beta 4, Y-linked (206769_at), score: -0.48
TNFRSF8tumor necrosis factor receptor superfamily, member 8 (206729_at), score: -1
TNK1tyrosine kinase, non-receptor, 1 (217149_x_at), score: -0.52
TRIM45tripartite motif-containing 45 (219923_at), score: -0.48
WDR25WD repeat domain 25 (219609_at), score: -0.52
WDR52WD repeat domain 52 (221103_s_at), score: 0.63
WDR55WD repeat domain 55 (219809_at), score: 0.47
WDTC1WD and tetratricopeptide repeats 1 (215497_s_at), score: -0.51
ZKSCAN4zinc finger with KRAB and SCAN domains 4 (213625_at), score: -0.5
ZNF117zinc finger protein 117 (207605_x_at), score: -0.56
ZNF510zinc finger protein 510 (206053_at), score: 0.62
ZNF749zinc finger protein 749 (215289_at), score: 0.61
ZNF814zinc finger protein 814 (60794_f_at), score: 0.68
Non-Entrez genes
Unknown, score:
HELP
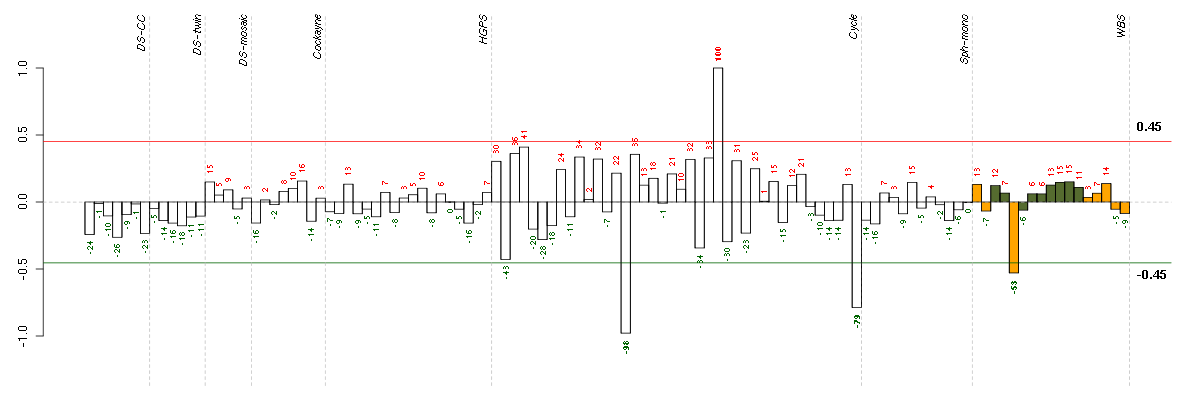
Conditions in the module, given in the same order as on the expression
plot above. Red color means over-expression, green under-expression in
the given condition.
The barplot below shows the condition (sample) scores. A separate bar
is shown for each sample, its height is the corresponding score of the
sample in the module. The red and green numbers on the bars are the
sample scores expressed in percents, i.e. 100% is 1.0.
The red and green lines show the module thresholds, samples above
the red line and below the green line are included in the module.
The different experiments that were part of the study, are separated
by dashed vertical lines.
— Click on the Help button again to close this help window.
| Id | sample | Experiment | ExpName | Array | Syndrome | Cell.line |
| E-TABM-263-raw-cel-1515485931.cel | 15 | 6 | Cycle | hgu133a2 | none | Cycle 1 |
| E-TABM-263-raw-cel-1515486431.cel | 40 | 6 | Cycle | hgu133a2 | none | Cycle 1 |
| 4319_WBS.CEL | 5 | 8 | WBS | hgu133plus2 | WBS | WBS 1 |
| E-TABM-263-raw-cel-1515486131.cel | 25 | 6 | Cycle | hgu133a2 | none | Cycle 1 |



© 2008-2010 Computational Biology Group, Department of Medical Genetics,
University of Lausanne, Switzerland
