Previous module |
Next module
Module #427, TG: 2.2, TC: 1.6, 73 probes, 73 Entrez genes, 10 conditions


HELP
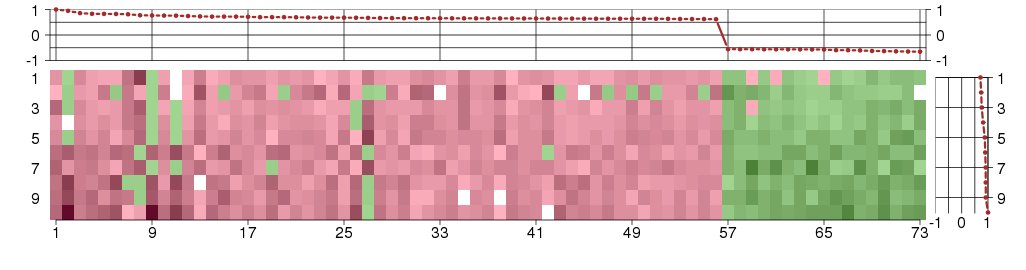
The image plot shows the color-coded level of gene expression, for the
genes and conditions in a given transcription module. The genes are on
the horizontal, the conditions on the vertical axis.
The genes are ordered according to their ISA gene scores, similarly
the conditions are ordered according to their condition scores. The
score of a gene means the «degree of inclusion» in
the module: a high score gene is essential in the module.
Condition scores can also be negative, that means that the genes of
the module are all down-regulated in the condition. Here the absolute
value of the score gives the «degree of inclusion».
The plots above and beside the expression matrix show the gene scores
and condition scores, respectively.
Note that the plot is interactive, you can see the name of the gene
and condition under the mouse cursor.
The expression matrix was normalized to have mean zero and standard
deviation one for every gene separately across all conditions
(i.e. not just for the conditions in the module).
— Click on the Help button again to close this help window.

Under-expression is coded with green,
over-expression with red color.
Help |
Hide |
Top
Help |
Show |
Top
The GO tree — Biological processes
HELP
This is one of three sections showing Gene Ontology enrichment of the
current module: in this case for biological processes.
The graph shows the hierarchy of the GO categories, their enrichment
for the current module is color coded, and the blue number beside the
category is the minus log ten p-value of the enrichment. (Calculated
using the standard hypergeometric test.) The color of the arrows code
«is a» (cyan) and «part of» relationships.
The tree was built the following way. First all GO terms with more
significant enrichment p-value than 0.05 were collected. Then all
paths from these terms to the root node of the GO tree were included
too. If a GO term is included more than once in the tree, then the
green numbers show 1) the id of the node, this makes it easier to find
other appereances of the term, and 2) the number of appearences.
Note that the same GO category might show up on the graph many
times. This is because the GO was «straightened» for this
graph, i.e. if there are more paths from a GO term to the root node of
the tree, all of them are included. The green numbers
Move the mouse cursor over the terms to get their definition. Clicking
on them takes you to the corresponding Gene Ontology web page.
If you cannot see a graph here at all, that means that there were no
significantly enriched GO categories, at the 0.05 level.
— Click on the Help button again to close this help window.

Help |
Hide |
Top
Help |
Show |
Top
The GO tree — Cellular Components
HELP
This is one of three sections showing Gene Ontology enrichment of the
current module: in this case for cellular components.
The graph shows the hierarchy of the GO categories, their enrichment
for the current module is color coded, and the blue number beside the
category is the minus log ten p-value of the enrichment. (Calculated
using the standard hypergeometric test.) The color of the arrows code
«is a» (cyan) and «part of» relationships.
The tree was built the following way. First all GO terms with more
significant enrichment p-value than 0.05 were collected. Then all
paths from these terms to the root node of the GO tree were included
too. If a GO term is included more than once in the tree, then the
green numbers show 1) the id of the node, this makes it easier to find
other appereances of the term, and 2) the number of appearences.
Note that the same GO category might show up on the graph many
times. This is because the GO was «straightened» for this
graph, i.e. if there are more paths from a GO term to the root node of
the tree, all of them are included. The green numbers
Move the mouse cursor over the terms to get their definition. Clicking
on them takes you to the corresponding Gene Ontology web page.
If you cannot see a graph here at all, that means that there were no
significantly enriched GO categories, at the 0.05 level.
— Click on the Help button again to close this help window.
Help |
Hide |
Top
Help |
Show |
Top
The GO tree — Molecular Function
HELP
This is one of three sections showing Gene Ontology enrichment of the
current module: in this case for molecular function.
The graph shows the hierarchy of the GO categories, their enrichment
for the current module is color coded, and the blue number beside the
category is the minus log ten p-value of the enrichment. (Calculated
using the standard hypergeometric test.) The color of the arrows code
«is a» (cyan) and «part of» relationships.
The tree was built the following way. First all GO terms with more
significant enrichment p-value than 0.05 were collected. Then all
paths from these terms to the root node of the GO tree were included
too. If a GO term is included more than once in the tree, then the
green numbers show 1) the id of the node, this makes it easier to find
other appereances of the term, and 2) the number of appearences.
Note that the same GO category might show up on the graph many
times. This is because the GO was «straightened» for this
graph, i.e. if there are more paths from a GO term to the root node of
the tree, all of them are included. The green numbers
Move the mouse cursor over the terms to get their definition. Clicking
on them takes you to the corresponding Gene Ontology web page.
If you cannot see a graph here at all, that means that there were no
significantly enriched GO categories, at the 0.05 level.
— Click on the Help button again to close this help window.
molecular_function
Elemental activities, such as catalysis or binding, describing the actions of a gene product at the molecular level. A given gene product may exhibit one or more molecular functions.
signal transducer activity
Mediates the transfer of a signal from the outside to the inside of a cell by means other than the introduction of the signal molecule itself into the cell.
receptor activity
Combining with an extracellular or intracellular messenger to initiate a change in cell activity.
transmembrane receptor activity
Combining with an extracellular or intracellular messenger to initiate a change in cell activity, and spanning to the membrane of either the cell or an organelle.
molecular transducer activity
The molecular function that accepts an input of one form and creates an output of a different form.
all
NA
Help |
Hide |
Top
Help |
Show |
Top
GO BP test for over-representation
HELP
List of all enriched GO categories (biological processes), at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module annotated with the given GO term, just by chance.
- Count
is the number of genes in the module annotated with the given GO
term.
- Size is the total number of genes (in our universe)
annotated with the GO term.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
GO category.
Clicking on the GO identifiers takes you to the Gene Ontology web
pages.
— Click on the Help button again to close this help window.
Help |
Hide |
Top
Help |
Show |
Top
GO CC test for over-representation
HELP
List of all enriched GO categories (cellular components), at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module annotated with the given GO term, just by chance.
- Count
is the number of genes in the module annotated with the given GO
term.
- Size is the total number of genes (in our universe)
annotated with the GO term.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
GO category.
Clicking on the GO identifiers takes you to the Gene Ontology web
pages.
— Click on the Help button again to close this help window.
| Id | Pvalue | ExpCount | Count | Size | Term |
| GO:0043209 | 3.886e-02 | 0.08179 | 2
ERMN, PLP1 | 6 | myelin sheath |
| GO:0045211 | 4.847e-02 | 1.036 | 5
CABP1, CHRM3, GABRA2, GRM3, LRFN2 | 76 | postsynaptic membrane |
Help |
Hide |
Top
Help |
Show |
Top
GO MF test for over-representation
HELP
List of all enriched GO categories (molecular function), at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module annotated with the given GO term, just by chance.
- Count
is the number of genes in the module annotated with the given GO
term.
- Size is the total number of genes (in our universe)
annotated with the GO term.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
GO category.
Clicking on the GO identifiers takes you to the Gene Ontology web
pages.
— Click on the Help button again to close this help window.
| Id | Pvalue | ExpCount | Count | Size | Term |
| GO:0004888 | 7.490e-03 | 3.444 | 12
AVPR1B, CHRM3, EPHA5, EVI2A, GABRA2, GRM3, HHIPL1, IL12RB2, IL1RAPL1, LANCL1, LGR5, PTPRA | 271 | transmembrane receptor activity |
Help |
Hide |
Top
Help |
Show |
Top
KEGG Pathway test for over-representation
HELP
List of all enriched KEGG pathways, at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module annotated with the given KEGG pathway, just by chance.
- Count
is the number of genes in the module annotated with the given KEGG
pathway.
- Size is the total number of genes (in our universe)
annotated with the KEGG pathway.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
KEGG pathway.
Clicking on the KEGG identifiers takes you to the KEGG web site.
— Click on the Help button again to close this help window.
Help |
Hide |
Top
Help |
Show |
Top
miRNA test for over-representation
HELP
List of all enriched miRNA families, at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module regulated by the given miRNA family, just by chance.
- Count
is the number of genes in the module regulated by the given miRNA
family.
- Size is the total number of genes (in our universe)
regulated with the given miRNA family.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
miRNA family.
The miRNA regulation data was taken from the TargetScan database.
(Only the conserved sites were used for the current analysis.)
Clicking on the miRNA names takes you to the TargetScan web site.
— Click on the Help button again to close this help window.
Help |
Hide |
Top
Help |
Show |
Top
Chromosome test for over-representation
HELP
List of all enriched Chromosomes, at the 0.05
p-value level.
The columns:
- ExpCount is the expected number of genes in the
module on the given chromosome, just by chance.
- Count
is the number of genes in the module on the given chromosome.
- Size is the total number of genes (in our universe)
on the given chromosome.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
chromosome.
— Click on the Help button again to close this help window.
HELP
A list of all genes in the current module, in alphabetical order. The
size of the text corresponds to the gene scores.
Text color indicates correlation and anti-correlation: genes of the
same color are correlated, both move up or down in the module samples
(listed below). Genes of different color are anti-correlated, they
have opposite behavior in the module samples.
Note, that text color of the individual genes should be interpreted
together with the coloring of the samples below. For
red samples,
red genes have a higher expression
(compared to the average gene expression level),
green genes have a lower
expression.
Green samples have opposite
behavior, in these red genes have a
lower expression, green genes
have a higher expression.
Note that some gene symbols may show up more than once, if many
probes match the same Entrez gene.
Genes with no Entrez mapping are given separately, with their
Affymetrics probe ID.
— Click on the Help button again to close this help window.
Entrez genes
AANATaralkylamine N-acetyltransferase (ENSG00000129673), score: 0.68
ADARB2adenosine deaminase, RNA-specific, B2 (ENSG00000185736), score: 0.69
AK2adenylate kinase 2 (ENSG00000004455), score: -0.63
AMMECR1LAMME chromosomal region gene 1-like (ENSG00000144233), score: -0.63
AMZ1archaelysin family metallopeptidase 1 (ENSG00000174945), score: 0.65
ATXN7ataxin 7 (ENSG00000163635), score: -0.59
AVPR1Barginine vasopressin receptor 1B (ENSG00000198049), score: 0.95
C12orf29chromosome 12 open reading frame 29 (ENSG00000133641), score: 0.64
C20orf103chromosome 20 open reading frame 103 (ENSG00000125869), score: 0.65
CABP1calcium binding protein 1 (ENSG00000157782), score: 0.65
CALHM1calcium homeostasis modulator 1 (ENSG00000185933), score: 0.67
CBLN4cerebellin 4 precursor (ENSG00000054803), score: 0.64
CD2APCD2-associated protein (ENSG00000198087), score: -0.56
CDH20cadherin 20, type 2 (ENSG00000101542), score: 0.71
CERCAMcerebral endothelial cell adhesion molecule (ENSG00000167123), score: 0.73
CHRM3cholinergic receptor, muscarinic 3 (ENSG00000133019), score: 0.64
CLCN3chloride channel 3 (ENSG00000109572), score: 0.72
CLDND1claudin domain containing 1 (ENSG00000080822), score: 0.65
CNDP1carnosine dipeptidase 1 (metallopeptidase M20 family) (ENSG00000150656), score: 0.66
CNIH4cornichon homolog 4 (Drosophila) (ENSG00000143771), score: -0.56
CNTN5contactin 5 (ENSG00000149972), score: 0.82
COL4A1collagen, type IV, alpha 1 (ENSG00000187498), score: -0.56
DPYSL4dihydropyrimidinase-like 4 (ENSG00000151640), score: 0.65
DSELdermatan sulfate epimerase-like (ENSG00000171451), score: 0.76
EPHA5EPH receptor A5 (ENSG00000145242), score: 0.64
EPHX4epoxide hydrolase 4 (ENSG00000172031), score: 0.62
ERMNermin, ERM-like protein (ENSG00000136541), score: 0.7
EVI2Aecotropic viral integration site 2A (ENSG00000126860), score: 0.66
FAM175Bfamily with sequence similarity 175, member B (ENSG00000165660), score: -0.56
FCHO2FCH domain only 2 (ENSG00000157107), score: -0.56
FNBP1Lformin binding protein 1-like (ENSG00000137942), score: -0.55
GABRA2gamma-aminobutyric acid (GABA) A receptor, alpha 2 (ENSG00000151834), score: 0.66
GPM6Bglycoprotein M6B (ENSG00000046653), score: 0.64
GRM3glutamate receptor, metabotropic 3 (ENSG00000198822), score: 0.7
HERPUD1homocysteine-inducible, endoplasmic reticulum stress-inducible, ubiquitin-like domain member 1 (ENSG00000051108), score: -0.56
HHIPL1HHIP-like 1 (ENSG00000182218), score: 0.72
HHLA1HERV-H LTR-associating 1 (ENSG00000132297), score: 0.76
IL12RB2interleukin 12 receptor, beta 2 (ENSG00000081985), score: 0.72
IL1RAPL1interleukin 1 receptor accessory protein-like 1 (ENSG00000169306), score: 0.83
IMPAD1inositol monophosphatase domain containing 1 (ENSG00000104331), score: 0.64
KBTBD3kelch repeat and BTB (POZ) domain containing 3 (ENSG00000182359), score: 0.74
KCNH8potassium voltage-gated channel, subfamily H (eag-related), member 8 (ENSG00000183960), score: 0.65
KIAA1429KIAA1429 (ENSG00000164944), score: -0.57
LANCL1LanC lantibiotic synthetase component C-like 1 (bacterial) (ENSG00000115365), score: 0.65
LGR5leucine-rich repeat-containing G protein-coupled receptor 5 (ENSG00000139292), score: 0.68
LIX1Lix1 homolog (chicken) (ENSG00000145721), score: 0.81
LRFN2leucine rich repeat and fibronectin type III domain containing 2 (ENSG00000156564), score: 0.66
MYO19myosin XIX (ENSG00000141140), score: -0.66
NGBneuroglobin (ENSG00000165553), score: 0.7
PHLPP1PH domain and leucine rich repeat protein phosphatase 1 (ENSG00000081913), score: 0.64
PIK3CDphosphoinositide-3-kinase, catalytic, delta polypeptide (ENSG00000171608), score: 0.86
PIP4K2Aphosphatidylinositol-5-phosphate 4-kinase, type II, alpha (ENSG00000150867), score: 0.66
PLP1proteolipid protein 1 (ENSG00000123560), score: 0.63
PMP2peripheral myelin protein 2 (ENSG00000147588), score: 0.65
PREX1phosphatidylinositol-3,4,5-trisphosphate-dependent Rac exchange factor 1 (ENSG00000124126), score: 0.68
PRPH2peripherin 2 (retinal degeneration, slow) (ENSG00000112619), score: 1
PRRG1proline rich Gla (G-carboxyglutamic acid) 1 (ENSG00000130962), score: 0.62
PTPRAprotein tyrosine phosphatase, receptor type, A (ENSG00000132670), score: 0.83
RNMTRNA (guanine-7-) methyltransferase (ENSG00000101654), score: 0.68
ROCK1Rho-associated, coiled-coil containing protein kinase 1 (ENSG00000067900), score: -0.6
RPS6KC1ribosomal protein S6 kinase, 52kDa, polypeptide 1 (ENSG00000136643), score: 0.7
RS1retinoschisin 1 (ENSG00000102104), score: 0.77
SMC5structural maintenance of chromosomes 5 (ENSG00000198887), score: -0.57
SMEK1SMEK homolog 1, suppressor of mek1 (Dictyostelium) (ENSG00000100796), score: -0.65
SRIsorcin (ENSG00000075142), score: 0.66
TMEFF2transmembrane protein with EGF-like and two follistatin-like domains 2 (ENSG00000144339), score: 0.65
TMEM179transmembrane protein 179 (ENSG00000189203), score: 0.63
TPBGtrophoblast glycoprotein (ENSG00000146242), score: 0.64
WDR26WD repeat domain 26 (ENSG00000162923), score: -0.59
WNT2Bwingless-type MMTV integration site family, member 2B (ENSG00000134245), score: 0.63
WNT3Awingless-type MMTV integration site family, member 3A (ENSG00000154342), score: 0.77
ZCCHC8zinc finger, CCHC domain containing 8 (ENSG00000033030), score: -0.64
ZNF536zinc finger protein 536 (ENSG00000198597), score: 0.64
Non-Entrez genes
Unknown, score:
HELP
Conditions in the module, given in the same order as on the expression
plot above. Red color means over-expression, green under-expression in
the given condition.
The barplot below shows the condition (sample) scores. A separate bar
is shown for each sample, its height is the corresponding score of the
sample in the module. The red and green numbers on the bars are the
sample scores expressed in percents, i.e. 100% is 1.0.
The height of each bar corresponds to the weighted
mean expression of the module genes. The weights are the gene scores
of the module and they are positive for the genes listed in
red above and they are negative for
the genes that are listed in
green.
Bars going up correspond to samples listed in
red (the ones that are different
enough to included in the module). In these samples
the red module genes are highly
expressed, and the green
module genes are lowly expressed. The behavior of the genes is the
opposite for bars going down.
The red and green lines show the module thresholds, samples above
the red line and below the green line are included in the module.
The different species and tissues that were part of the study, are separated
by dashed vertical lines.
— Click on the Help button again to close this help window.
| Id | species | tissue | sex | individual |
| hsa_br_m1_ca1 | hsa | br | m | 1 |
| hsa_br_m6_ca1 | hsa | br | m | 6 |
| hsa_br_m2_ca1 | hsa | br | m | 2 |
| hsa_br_f_ca1 | hsa | br | f | _ |
| hsa_br_m3_ca1 | hsa | br | m | 3 |
| oan_cb_f_ca1 | oan | cb | f | _ |
| hsa_br_m7_ca1 | hsa | br | m | 7 |
| oan_br_f_ca1 | oan | br | f | _ |
| oan_cb_m_ca1 | oan | cb | m | _ |
| oan_br_m_ca1 | oan | br | m | _ |



© 2008-2010 Computational Biology Group, Department of Medical Genetics,
University of Lausanne, Switzerland