Overview
|
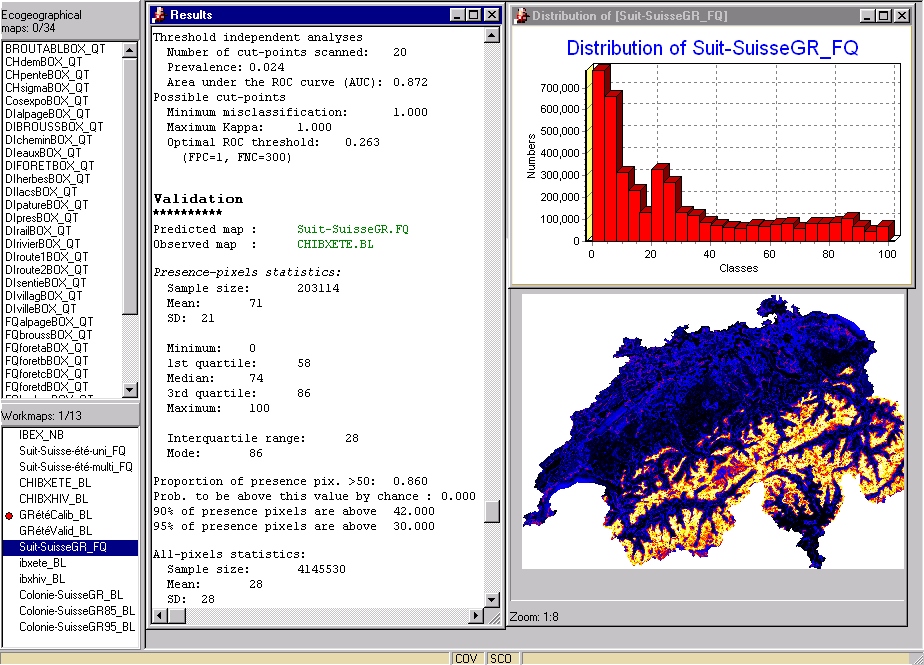
Biomapper is a kit of GIS- and statistical tools
designed to build habitat suitability (HS) models and maps for any kind
of animal or plant. It is centred on the
Ecological
Niche Factor Analysis (ENFA) that allows to compute HS models without
the need of absence data.
More precisely, it can deal with the following tasks:
-
Preparing the ecogeographical maps in order
to use them as input for the ENFA (e.g. computing frequency of occurrence
map, standardisation, masking, etc.)
-
Exploring and comparing them by mean of descriptive
statistics (distribution analysis, etc.)
-
Computing the Ecological Niche Factor Analysis
and exploring its output.
-
Computing a Habitat Suitability map
Biomapper is designed to be autonomous but as it uses the same file format
as the GIS software Idrisi, they
can transparently work in conjunction. |
|
Notes
|
-
Biomapper doesn't need absence data. Yes I
already said this but it is a very important and rare property and it is
worth to be repeated again and again.
-
Biomapper can be installed on any PC running
Windows
95, Windows NT 4.0 or later, with at least 5 Mb
free on the hard disk.
-
You don't need Idrisi to work with Biomapper.
-
Biomapper was designed with huge files in
mind. It was actually tested with up to 30 maps of 32 Mb each. As far as
I know, the only limitations are the free memory of your computer, the
size of your hard disk and the amount of your patience!
-
I tried to make it easy to understand and
practical.
So far, actual users seemed fairly able to make their way through it. A
help
file give a few information and an extensive step-by-step modus
operandi.
-
Biomapper is at a late stage of beta-testing. It means that it is continuously
improved, new features are regularly added (I could even decide
to implement something you specially need) and that it is not bug-free
(but it was nevertheless thoroughly tested by several users including myself).
-
Biomapper and its central statistical procedure, ENFA,
are brand new (Hirzel
et al., in revision).
-
The ENFA proved to produce highly accurate results
even with poor input data. In fact, it is quite robust
to data quality and quantity (Hirzel et al., in revision)
-
It is based on presence data only.
|