Previous module |
Next module
Module #700, TG: 2.6, TC: 2, 137 probes, 137 Entrez genes, 6 conditions


HELP
The image plot shows the color-coded level of gene expression, for the
genes and conditions in a given transcription module. The genes are on
the horizontal, the conditions on the vertical axis.
The genes are ordered according to their ISA gene scores, similarly
the conditions are ordered according to their condition scores. The
score of a gene means the «degree of inclusion» in
the module: a high score gene is essential in the module.
Condition scores can also be negative, that means that the genes of
the module are all down-regulated in the condition. Here the absolute
value of the score gives the «degree of inclusion».
The plots above and beside the expression matrix show the gene scores
and condition scores, respectively.
Note that the plot is interactive, you can see the name of the gene
and condition under the mouse cursor.
The expression matrix was normalized to have mean zero and standard
deviation one for every gene separately across all conditions
(i.e. not just for the conditions in the module).
— Click on the Help button again to close this help window.

Under-expression is coded with green,
over-expression with red color.
Help |
Hide |
Top
Help |
Show |
Top
The GO tree — Biological processes
HELP
This is one of three sections showing Gene Ontology enrichment of the
current module: in this case for biological processes.
The graph shows the hierarchy of the GO categories, their enrichment
for the current module is color coded, and the blue number beside the
category is the minus log ten p-value of the enrichment. (Calculated
using the standard hypergeometric test.) The color of the arrows code
«is a» (cyan) and «part of» relationships.
The tree was built the following way. First all GO terms with more
significant enrichment p-value than 0.05 were collected. Then all
paths from these terms to the root node of the GO tree were included
too. If a GO term is included more than once in the tree, then the
green numbers show 1) the id of the node, this makes it easier to find
other appereances of the term, and 2) the number of appearences.
Note that the same GO category might show up on the graph many
times. This is because the GO was «straightened» for this
graph, i.e. if there are more paths from a GO term to the root node of
the tree, all of them are included. The green numbers
Move the mouse cursor over the terms to get their definition. Clicking
on them takes you to the corresponding Gene Ontology web page.
If you cannot see a graph here at all, that means that there were no
significantly enriched GO categories, at the 0.05 level.
— Click on the Help button again to close this help window.

Help |
Hide |
Top
Help |
Show |
Top
The GO tree — Cellular Components
HELP
This is one of three sections showing Gene Ontology enrichment of the
current module: in this case for cellular components.
The graph shows the hierarchy of the GO categories, their enrichment
for the current module is color coded, and the blue number beside the
category is the minus log ten p-value of the enrichment. (Calculated
using the standard hypergeometric test.) The color of the arrows code
«is a» (cyan) and «part of» relationships.
The tree was built the following way. First all GO terms with more
significant enrichment p-value than 0.05 were collected. Then all
paths from these terms to the root node of the GO tree were included
too. If a GO term is included more than once in the tree, then the
green numbers show 1) the id of the node, this makes it easier to find
other appereances of the term, and 2) the number of appearences.
Note that the same GO category might show up on the graph many
times. This is because the GO was «straightened» for this
graph, i.e. if there are more paths from a GO term to the root node of
the tree, all of them are included. The green numbers
Move the mouse cursor over the terms to get their definition. Clicking
on them takes you to the corresponding Gene Ontology web page.
If you cannot see a graph here at all, that means that there were no
significantly enriched GO categories, at the 0.05 level.
— Click on the Help button again to close this help window.
Help |
Hide |
Top
Help |
Show |
Top
The GO tree — Molecular Function
HELP
This is one of three sections showing Gene Ontology enrichment of the
current module: in this case for molecular function.
The graph shows the hierarchy of the GO categories, their enrichment
for the current module is color coded, and the blue number beside the
category is the minus log ten p-value of the enrichment. (Calculated
using the standard hypergeometric test.) The color of the arrows code
«is a» (cyan) and «part of» relationships.
The tree was built the following way. First all GO terms with more
significant enrichment p-value than 0.05 were collected. Then all
paths from these terms to the root node of the GO tree were included
too. If a GO term is included more than once in the tree, then the
green numbers show 1) the id of the node, this makes it easier to find
other appereances of the term, and 2) the number of appearences.
Note that the same GO category might show up on the graph many
times. This is because the GO was «straightened» for this
graph, i.e. if there are more paths from a GO term to the root node of
the tree, all of them are included. The green numbers
Move the mouse cursor over the terms to get their definition. Clicking
on them takes you to the corresponding Gene Ontology web page.
If you cannot see a graph here at all, that means that there were no
significantly enriched GO categories, at the 0.05 level.
— Click on the Help button again to close this help window.
molecular_function
Elemental activities, such as catalysis or binding, describing the actions of a gene product at the molecular level. A given gene product may exhibit one or more molecular functions.
nucleic acid binding
Interacting selectively with any nucleic acid.
binding
The selective, often stoichiometric, interaction of a molecule with one or more specific sites on another molecule.
all
This term is the most general term possible
Help |
Hide |
Top
Help |
Show |
Top
GO BP test for over-representation
HELP
List of all enriched GO categories (biological processes), at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module annotated with the given GO term, just by chance.
- Count
is the number of genes in the module annotated with the given GO
term.
- Size is the total number of genes (in our universe)
annotated with the GO term.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
GO category.
Clicking on the GO identifiers takes you to the Gene Ontology web
pages.
— Click on the Help button again to close this help window.
Help |
Hide |
Top
Help |
Show |
Top
GO CC test for over-representation
HELP
List of all enriched GO categories (cellular components), at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module annotated with the given GO term, just by chance.
- Count
is the number of genes in the module annotated with the given GO
term.
- Size is the total number of genes (in our universe)
annotated with the GO term.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
GO category.
Clicking on the GO identifiers takes you to the Gene Ontology web
pages.
— Click on the Help button again to close this help window.
Help |
Hide |
Top
Help |
Show |
Top
GO MF test for over-representation
HELP
List of all enriched GO categories (molecular function), at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module annotated with the given GO term, just by chance.
- Count
is the number of genes in the module annotated with the given GO
term.
- Size is the total number of genes (in our universe)
annotated with the GO term.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
GO category.
Clicking on the GO identifiers takes you to the Gene Ontology web
pages.
— Click on the Help button again to close this help window.
| Id | Pvalue | ExpCount | Count | Size | Term |
| GO:0003676 | 3.190e-03 | 22.36 | 41
AKAP8, BTF3L2, CGGBP1, CIRBP, CNOT6, DDX6, EEF1D, FBXL11, FUBP1, G3BP1, HEY1, IREB2, JARID2, MKRN1, MLLT10, MRPL44, NACA, PBX2, PCGF2, POGZ, POLR1B, RPL14, RPL35A, RPLP2, RPS19, SCML2, SFRS11, SYCP1, XRCC2, ZBTB39, ZC3H7B, ZNF492, ZNF506, ZNF528, ZNF552, ZNF611, ZNF639, ZNF747, ZNF770, ZNF816A, ZSCAN12 | 1801 | nucleic acid binding |
| GO:0008270 | 2.683e-02 | 14.48 | 28
AKAP8, CISD3, COX5B, FBXL11, FBXO41, LIMK1, MEFV, MKRN1, MLLT10, PCGF2, PHF8, POGZ, POLR1B, SLC30A5, TIMM8A, TRIM36, TRIT1, ZBTB39, ZC3H7B, ZNF492, ZNF506, ZNF528, ZNF552, ZNF611, ZNF639, ZNF770, ZNF816A, ZSCAN12 | 1166 | zinc ion binding |
| GO:0046914 | 2.811e-02 | 17.67 | 32
AKAP8, CISD3, COX5B, CYP2B6, FBXL11, FBXO41, IREB2, LIMK1, MEFV, METAP2, MKRN1, MLLT10, PCGF2, PHF8, POGZ, POLR1B, SCD5, SLC30A5, TIMM8A, TRIM36, TRIT1, ZBTB39, ZC3H7B, ZNF492, ZNF506, ZNF528, ZNF552, ZNF611, ZNF639, ZNF770, ZNF816A, ZSCAN12 | 1423 | transition metal ion binding |
Help |
Hide |
Top
Help |
Show |
Top
KEGG Pathway test for over-representation
HELP
List of all enriched KEGG pathways, at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module annotated with the given KEGG pathway, just by chance.
- Count
is the number of genes in the module annotated with the given KEGG
pathway.
- Size is the total number of genes (in our universe)
annotated with the KEGG pathway.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
KEGG pathway.
Clicking on the KEGG identifiers takes you to the KEGG web site.
— Click on the Help button again to close this help window.
Help |
Hide |
Top
Help |
Show |
Top
miRNA test for over-representation
HELP
List of all enriched miRNA families, at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module regulated by the given miRNA family, just by chance.
- Count
is the number of genes in the module regulated by the given miRNA
family.
- Size is the total number of genes (in our universe)
regulated with the given miRNA family.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
miRNA family.
The miRNA regulation data was taken from the TargetScan database.
(Only the conserved sites were used for the current analysis.)
Clicking on the miRNA names takes you to the TargetScan web site.
— Click on the Help button again to close this help window.
Help |
Hide |
Top
Help |
Show |
Top
Chromosome test for over-representation
HELP
List of all enriched Chromosomes, at the 0.05
p-value level.
The columns:
- ExpCount is the expected number of genes in the
module on the given chromosome, just by chance.
- Count
is the number of genes in the module on the given chromosome.
- Size is the total number of genes (in our universe)
on the given chromosome.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
chromosome.
— Click on the Help button again to close this help window.
HELP
A list of all genes in the current module, in alphabetical order. The
size of the text corresponds to the gene scores.
Note that some gene symbols may show up more than once, if many
probes match the same Entrez gene.
Genes with no Entrez mapping are given separately, with their
Affymetrics probe ID.
— Click on the Help button again to close this help window.
Entrez genes
ACOT11acyl-CoA thioesterase 11 (216103_at), score: 0.74
ADORA2Aadenosine A2a receptor (205013_s_at), score: 0.83
AKAP8A kinase (PRKA) anchor protein 8 (203848_at), score: 0.71
ALDOAP2aldolase A, fructose-bisphosphate pseudogene 2 (211617_at), score: 0.75
ALMS1Alstrom syndrome 1 (214707_x_at), score: 0.9
APBB2amyloid beta (A4) precursor protein-binding, family B, member 2 (212972_x_at), score: 0.98
ARHGEF7Rho guanine nucleotide exchange factor (GEF) 7 (202548_s_at), score: 0.74
BCL9B-cell CLL/lymphoma 9 (204129_at), score: 0.78
BTF3L2basic transcription factor 3, like 2 (217461_x_at), score: 0.72
C11orf57chromosome 11 open reading frame 57 (218314_s_at), score: 0.75
C17orf86chromosome 17 open reading frame 86 (221621_at), score: 0.94
C4orf10chromosome 4 open reading frame 10 (214123_s_at), score: 0.76
C6orf106chromosome 6 open reading frame 106 (217925_s_at), score: 0.75
C6orf62chromosome 6 open reading frame 62 (222309_at), score: 0.8
CDC14ACDC14 cell division cycle 14 homolog A (S. cerevisiae) (205288_at), score: 0.74
CDR1cerebellar degeneration-related protein 1, 34kDa (207276_at), score: 0.78
CGGBP1CGG triplet repeat binding protein 1 (214050_at), score: 0.89
CIRBPcold inducible RNA binding protein (200811_at), score: 0.75
CISD3CDGSH iron sulfur domain 3 (213551_x_at), score: 0.75
CNOT6CCR4-NOT transcription complex, subunit 6 (217970_s_at), score: 0.79
COX5Bcytochrome c oxidase subunit Vb (213736_at), score: 0.8
CYP2B6cytochrome P450, family 2, subfamily B, polypeptide 6 (217133_x_at), score: 0.74
DAPP1dual adaptor of phosphotyrosine and 3-phosphoinositides (219290_x_at), score: 0.88
DDX6DEAD (Asp-Glu-Ala-Asp) box polypeptide 6 (204909_at), score: 0.75
DKFZp686O1327hypothetical gene supported by BC043549; BX648102 (216877_at), score: 0.79
DNAH3dynein, axonemal, heavy chain 3 (220725_x_at), score: 0.92
EEF1Deukaryotic translation elongation factor 1 delta (guanine nucleotide exchange protein) (214395_x_at), score: 0.73
EPB41L1erythrocyte membrane protein band 4.1-like 1 (212339_at), score: 0.81
FAM134Afamily with sequence similarity 134, member A (222129_at), score: 0.83
FBXL11F-box and leucine-rich repeat protein 11 (208989_s_at), score: 0.79
FBXO41F-box protein 41 (44040_at), score: 0.74
FBXW12F-box and WD repeat domain containing 12 (215600_x_at), score: 0.81
FCARFc fragment of IgA, receptor for (211305_x_at), score: 0.84
FLJ11292hypothetical protein FLJ11292 (220828_s_at), score: 1
FLJ23172hypothetical LOC389177 (217016_x_at), score: 0.79
FNBP4formin binding protein 4 (212232_at), score: 0.81
FUBP1far upstream element (FUSE) binding protein 1 (212847_at), score: 0.77
G3BP1GTPase activating protein (SH3 domain) binding protein 1 (222187_x_at), score: 0.98
GTPBP3GTP binding protein 3 (mitochondrial) (213835_x_at), score: 0.78
HCG2P7HLA complex group 2 pseudogene 7 (216229_x_at), score: 0.88
HEY1hairy/enhancer-of-split related with YRPW motif 1 (44783_s_at), score: 0.8
IBD12Inflammatory bowel disease 12 (215373_x_at), score: 0.85
INSRinsulin receptor (213792_s_at), score: 0.72
IREB2iron-responsive element binding protein 2 (214666_x_at), score: 0.71
ITPKBinositol 1,4,5-trisphosphate 3-kinase B (203723_at), score: 0.72
JARID2jumonji, AT rich interactive domain 2 (203297_s_at), score: 0.75
KIAA0894KIAA0894 protein (207436_x_at), score: 0.71
LAMP1lysosomal-associated membrane protein 1 (213728_at), score: 0.76
LETM1leucine zipper-EF-hand containing transmembrane protein 1 (222006_at), score: 0.79
LIMK1LIM domain kinase 1 (204357_s_at), score: 0.78
LOC100128701heterogeneous nuclear ribonucleoprotein A1-like 2 pseudogene (216497_at), score: 0.85
LOC100128836similar to heterogeneous nuclear ribonucleoprotein A1 (217353_at), score: 0.82
LOC100129624hypothetical LOC100129624 (210748_at), score: 0.84
LOC100130233similar to NPM1 protein (216387_x_at), score: 0.75
LOC100134401hypothetical protein LOC100134401 (213605_s_at), score: 0.76
LOC152719hypothetical protein LOC152719 (215978_x_at), score: 0.71
LOC171220destrin-2 pseudogene (211325_x_at), score: 0.86
LOC643313similar to hypothetical protein LOC284701 (211050_x_at), score: 0.88
LOC644617hypothetical LOC644617 (221235_s_at), score: 0.84
LOC647070hypothetical LOC647070 (215467_x_at), score: 0.87
LOC728844hypothetical LOC728844 (222040_at), score: 0.73
MAGT1magnesium transporter 1 (210596_at), score: 0.75
MAP2K7mitogen-activated protein kinase kinase 7 (216206_x_at), score: 0.79
MAP3K9mitogen-activated protein kinase kinase kinase 9 (213927_at), score: 0.7
MCL1myeloid cell leukemia sequence 1 (BCL2-related) (214057_at), score: 0.85
MEFVMediterranean fever (208262_x_at), score: 0.72
METAP2methionyl aminopeptidase 2 (202015_x_at), score: 0.88
METTL7Amethyltransferase like 7A (211424_x_at), score: 0.89
MFSD11major facilitator superfamily domain containing 11 (221192_x_at), score: 0.78
MKRN1makorin ring finger protein 1 (208082_x_at), score: 0.77
MLLT10myeloid/lymphoid or mixed-lineage leukemia (trithorax homolog, Drosophila); translocated to, 10 (216506_x_at), score: 0.75
MRPL44mitochondrial ribosomal protein L44 (218202_x_at), score: 0.79
NACAnascent polypeptide-associated complex alpha subunit (222018_at), score: 0.71
OPHN1oligophrenin 1 (206323_x_at), score: 0.73
PBX2pre-B-cell leukemia homeobox 2 (202876_s_at), score: 0.76
PCGF2polycomb group ring finger 2 (203793_x_at), score: 0.74
PELI2pellino homolog 2 (Drosophila) (219132_at), score: 0.8
PHF8PHD finger protein 8 (212916_at), score: 0.78
PIP4K2Cphosphatidylinositol-5-phosphate 4-kinase, type II, gamma (218942_at), score: 0.79
POGZpogo transposable element with ZNF domain (215281_x_at), score: 0.83
POLR1Bpolymerase (RNA) I polypeptide B, 128kDa (220113_x_at), score: 0.78
POM121L9PPOM121 membrane glycoprotein-like 9 (rat) pseudogene (222253_s_at), score: 0.73
PRINSpsoriasis associated RNA induced by stress (non-protein coding) (216051_x_at), score: 0.86
RGS5regulator of G-protein signaling 5 (218353_at), score: 0.7
RHEBRas homolog enriched in brain (213409_s_at), score: 0.78
RPL14ribosomal protein L14 (219138_at), score: 0.79
RPL21P37ribosomal protein L21 pseudogene 37 (216479_at), score: 0.89
RPL23AP32ribosomal protein L23a pseudogene 32 (207283_at), score: 0.72
RPL35Aribosomal protein L35a (215208_x_at), score: 0.78
RPLP2ribosomal protein, large, P2 (200908_s_at), score: 0.76
RPS10P3ribosomal protein S10 pseudogene 3 (217336_at), score: 0.73
RPS19ribosomal protein S19 (202648_at), score: 0.75
RPS3AP47ribosomal protein S3a pseudogene 47 (216823_at), score: 0.9
SAPS2SAPS domain family, member 2 (202792_s_at), score: 0.75
SCD5stearoyl-CoA desaturase 5 (220232_at), score: 0.75
SCML2sex comb on midleg-like 2 (Drosophila) (206147_x_at), score: 0.72
SFRS11splicing factor, arginine/serine-rich 11 (213742_at), score: 0.76
SH3BP2SH3-domain binding protein 2 (217257_at), score: 0.88
SH3GL3SH3-domain GRB2-like 3 (211565_at), score: 0.88
SKP1S-phase kinase-associated protein 1 (200719_at), score: 0.82
SLC25A44solute carrier family 25, member 44 (32091_at), score: 0.79
SLC30A5solute carrier family 30 (zinc transporter), member 5 (220181_x_at), score: 0.99
SLC35F2solute carrier family 35, member F2 (218826_at), score: 0.73
SLC6A6solute carrier family 6 (neurotransmitter transporter, taurine), member 6 (205921_s_at), score: 0.73
SMEK2SMEK homolog 2, suppressor of mek1 (Dictyostelium) (222270_at), score: 0.79
SNX15sorting nexin 15 (205482_x_at), score: 0.7
SPATA2spermatogenesis associated 2 (204433_s_at), score: 0.81
SPG21spastic paraplegia 21 (autosomal recessive, Mast syndrome) (215383_x_at), score: 0.76
SPINLW1serine peptidase inhibitor-like, with Kunitz and WAP domains 1 (eppin) (206318_at), score: 0.91
SPNsialophorin (206057_x_at), score: 0.97
SPTLC3serine palmitoyltransferase, long chain base subunit 3 (220456_at), score: 0.95
SYCP1synaptonemal complex protein 1 (206740_x_at), score: 0.76
TCTN2tectonic family member 2 (206438_x_at), score: 0.82
TIMM8Atranslocase of inner mitochondrial membrane 8 homolog A (yeast) (210800_at), score: 1
TNPO3transportin 3 (212317_at), score: 0.81
TP53TG3TP53 target 3 (220167_s_at), score: 0.7
TRIM36tripartite motif-containing 36 (219736_at), score: 0.78
TRIT1tRNA isopentenyltransferase 1 (218617_at), score: 0.74
TRPV1transient receptor potential cation channel, subfamily V, member 1 (219632_s_at), score: 0.7
TUBA3Ctubulin, alpha 3c (210527_x_at), score: 0.7
UBQLN4ubiquilin 4 (222252_x_at), score: 0.86
UGT2B28UDP glucuronosyltransferase 2 family, polypeptide B28 (211682_x_at), score: 0.75
VAMP2vesicle-associated membrane protein 2 (synaptobrevin 2) (201557_at), score: 0.85
XRCC2X-ray repair complementing defective repair in Chinese hamster cells 2 (207598_x_at), score: 0.79
YTHDF1YTH domain family, member 1 (221741_s_at), score: 0.71
ZBTB39zinc finger and BTB domain containing 39 (205256_at), score: 0.9
ZC3H7Bzinc finger CCCH-type containing 7B (206169_x_at), score: 0.87
ZNF492zinc finger protein 492 (215532_x_at), score: 0.85
ZNF506zinc finger protein 506 (221626_at), score: 0.81
ZNF528zinc finger protein 528 (215019_x_at), score: 0.81
ZNF552zinc finger protein 552 (219741_x_at), score: 0.8
ZNF611zinc finger protein 611 (208137_x_at), score: 0.76
ZNF639zinc finger protein 639 (218413_s_at), score: 0.78
ZNF747zinc finger protein 747 (206180_x_at), score: 0.74
ZNF770zinc finger protein 770 (220608_s_at), score: 0.84
ZNF816Azinc finger protein 816A (217541_x_at), score: 0.89
ZSCAN12zinc finger and SCAN domain containing 12 (206507_at), score: 0.74
Non-Entrez genes
Unknown, score:
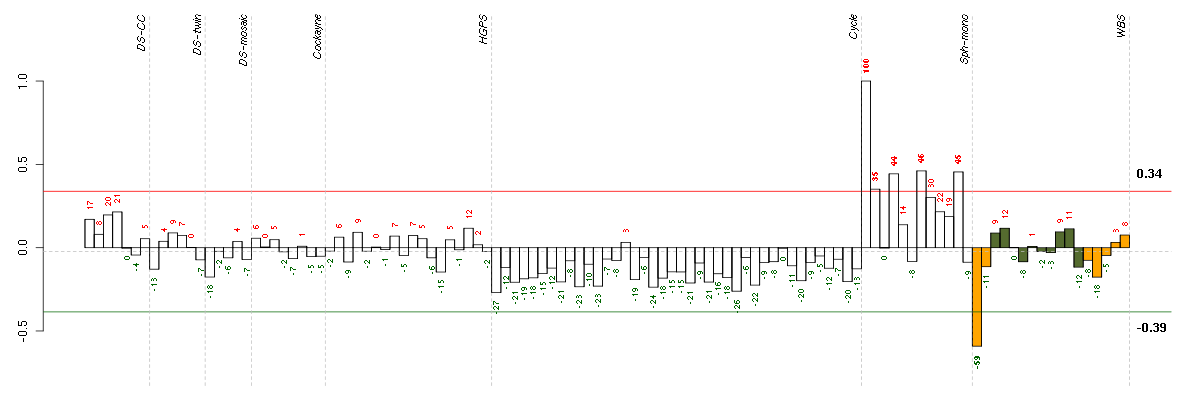
HELP
Conditions in the module, given in the same order as on the expression
plot above. Red color means over-expression, green under-expression in
the given condition.
The barplot below shows the condition (sample) scores. A separate bar
is shown for each sample, its height is the corresponding score of the
sample in the module. The red and green numbers on the bars are the
sample scores expressed in percents, i.e. 100% is 1.0.
The red and green lines show the module thresholds, samples above
the red line and below the green line are included in the module.
The different experiments that were part of the study, are separated
by dashed vertical lines.
— Click on the Help button again to close this help window.
| Id | sample | Experiment | ExpName | Array | Syndrome | Cell.line |
| 10358_WBS.CEL | 1 | 8 | WBS | hgu133plus2 | WBS | WBS 1 |
| E-GEOD-4219-raw-cel-1311956138.cel | 4 | 7 | Sph-mono | hgu133plus2 | none | Sph-mon 1 |
| E-GEOD-4219-raw-cel-1311956275.cel | 8 | 7 | Sph-mono | hgu133plus2 | none | Sph-mon 1 |
| E-GEOD-4219-raw-cel-1311956634.cel | 19 | 7 | Sph-mono | hgu133plus2 | none | Sph-mon 1 |
| E-GEOD-4219-raw-cel-1311956398.cel | 12 | 7 | Sph-mono | hgu133plus2 | none | Sph-mon 1 |
| E-GEOD-4219-raw-cel-1311956083.cel | 2 | 7 | Sph-mono | hgu133plus2 | none | Sph-mon 1 |



© 2008-2010 Computational Biology Group, Department of Medical Genetics,
University of Lausanne, Switzerland
