Previous module |
Next module
Module #742, TG: 2.6, TC: 1.8, 126 probes, 126 Entrez genes, 7 conditions


HELP
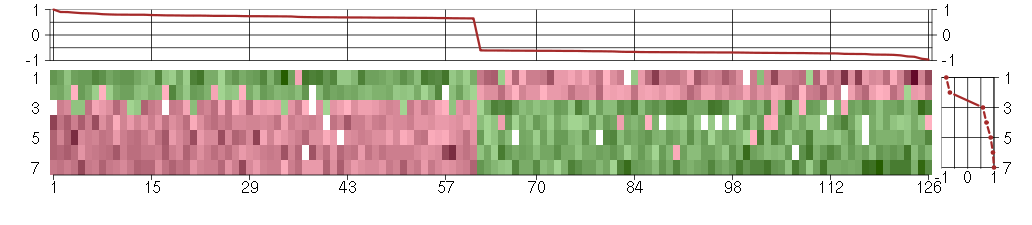
The image plot shows the color-coded level of gene expression, for the
genes and conditions in a given transcription module. The genes are on
the horizontal, the conditions on the vertical axis.
The genes are ordered according to their ISA gene scores, similarly
the conditions are ordered according to their condition scores. The
score of a gene means the «degree of inclusion» in
the module: a high score gene is essential in the module.
Condition scores can also be negative, that means that the genes of
the module are all down-regulated in the condition. Here the absolute
value of the score gives the «degree of inclusion».
The plots above and beside the expression matrix show the gene scores
and condition scores, respectively.
Note that the plot is interactive, you can see the name of the gene
and condition under the mouse cursor.
The expression matrix was normalized to have mean zero and standard
deviation one for every gene separately across all conditions
(i.e. not just for the conditions in the module).
— Click on the Help button again to close this help window.

Under-expression is coded with green,
over-expression with red color.
Help |
Hide |
Top
Help |
Show |
Top
The GO tree — Biological processes
HELP
This is one of three sections showing Gene Ontology enrichment of the
current module: in this case for biological processes.
The graph shows the hierarchy of the GO categories, their enrichment
for the current module is color coded, and the blue number beside the
category is the minus log ten p-value of the enrichment. (Calculated
using the standard hypergeometric test.) The color of the arrows code
«is a» (cyan) and «part of» relationships.
The tree was built the following way. First all GO terms with more
significant enrichment p-value than 0.05 were collected. Then all
paths from these terms to the root node of the GO tree were included
too. If a GO term is included more than once in the tree, then the
green numbers show 1) the id of the node, this makes it easier to find
other appereances of the term, and 2) the number of appearences.
Note that the same GO category might show up on the graph many
times. This is because the GO was «straightened» for this
graph, i.e. if there are more paths from a GO term to the root node of
the tree, all of them are included. The green numbers
Move the mouse cursor over the terms to get their definition. Clicking
on them takes you to the corresponding Gene Ontology web page.
If you cannot see a graph here at all, that means that there were no
significantly enriched GO categories, at the 0.05 level.
— Click on the Help button again to close this help window.

Help |
Hide |
Top
Help |
Show |
Top
The GO tree — Cellular Components
HELP
This is one of three sections showing Gene Ontology enrichment of the
current module: in this case for cellular components.
The graph shows the hierarchy of the GO categories, their enrichment
for the current module is color coded, and the blue number beside the
category is the minus log ten p-value of the enrichment. (Calculated
using the standard hypergeometric test.) The color of the arrows code
«is a» (cyan) and «part of» relationships.
The tree was built the following way. First all GO terms with more
significant enrichment p-value than 0.05 were collected. Then all
paths from these terms to the root node of the GO tree were included
too. If a GO term is included more than once in the tree, then the
green numbers show 1) the id of the node, this makes it easier to find
other appereances of the term, and 2) the number of appearences.
Note that the same GO category might show up on the graph many
times. This is because the GO was «straightened» for this
graph, i.e. if there are more paths from a GO term to the root node of
the tree, all of them are included. The green numbers
Move the mouse cursor over the terms to get their definition. Clicking
on them takes you to the corresponding Gene Ontology web page.
If you cannot see a graph here at all, that means that there were no
significantly enriched GO categories, at the 0.05 level.
— Click on the Help button again to close this help window.
Help |
Hide |
Top
Help |
Show |
Top
The GO tree — Molecular Function
HELP
This is one of three sections showing Gene Ontology enrichment of the
current module: in this case for molecular function.
The graph shows the hierarchy of the GO categories, their enrichment
for the current module is color coded, and the blue number beside the
category is the minus log ten p-value of the enrichment. (Calculated
using the standard hypergeometric test.) The color of the arrows code
«is a» (cyan) and «part of» relationships.
The tree was built the following way. First all GO terms with more
significant enrichment p-value than 0.05 were collected. Then all
paths from these terms to the root node of the GO tree were included
too. If a GO term is included more than once in the tree, then the
green numbers show 1) the id of the node, this makes it easier to find
other appereances of the term, and 2) the number of appearences.
Note that the same GO category might show up on the graph many
times. This is because the GO was «straightened» for this
graph, i.e. if there are more paths from a GO term to the root node of
the tree, all of them are included. The green numbers
Move the mouse cursor over the terms to get their definition. Clicking
on them takes you to the corresponding Gene Ontology web page.
If you cannot see a graph here at all, that means that there were no
significantly enriched GO categories, at the 0.05 level.
— Click on the Help button again to close this help window.
Help |
Hide |
Top
Help |
Show |
Top
GO BP test for over-representation
HELP
List of all enriched GO categories (biological processes), at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module annotated with the given GO term, just by chance.
- Count
is the number of genes in the module annotated with the given GO
term.
- Size is the total number of genes (in our universe)
annotated with the GO term.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
GO category.
Clicking on the GO identifiers takes you to the Gene Ontology web
pages.
— Click on the Help button again to close this help window.
| Id | Pvalue | ExpCount | Count | Size | Term |
| GO:0007218 | 4.329e-02 | 0.4252 | 4
GPR144, GPR56, LPHN1, NXPH3 | 33 | neuropeptide signaling pathway |
Help |
Hide |
Top
Help |
Show |
Top
GO CC test for over-representation
HELP
List of all enriched GO categories (cellular components), at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module annotated with the given GO term, just by chance.
- Count
is the number of genes in the module annotated with the given GO
term.
- Size is the total number of genes (in our universe)
annotated with the GO term.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
GO category.
Clicking on the GO identifiers takes you to the Gene Ontology web
pages.
— Click on the Help button again to close this help window.
| Id | Pvalue | ExpCount | Count | Size | Term |
| GO:0005576 | 3.222e-02 | 9.006 | 19
ADAMTS7, APP, COL11A2, DMBT1, EMCN, EPOR, FLRT3, GDF9, GFOD1, HAMP, HGF, MUC5AC, NDP, OLFML2B, PRLH, REG3A, SAA4, SEMA3F, VEGFB | 700 | extracellular region |
| GO:0044459 | 3.446e-02 | 11.26 | 22
ABCA7, ADORA1, APP, BCAM, CALB2, CD79B, CHRNB2, EPOR, FLRT3, GPR56, ITGAL, JUP, KCTD15, LILRB3, PAK1, PARVB, PXN, RASGRP3, SLC29A1, SLC6A11, STIM1, TGFBR2 | 875 | plasma membrane part |
| GO:0031093 | 3.492e-02 | 0.2316 | 3
APP, HGF, VEGFB | 18 | platelet alpha granule lumen |
| GO:0005887 | 3.770e-02 | 7.063 | 16
ADORA1, APP, BCAM, CD79B, CHRNB2, EPOR, FLRT3, GPR56, ITGAL, KCTD15, LILRB3, RASGRP3, SLC29A1, SLC6A11, STIM1, TGFBR2 | 549 | integral to plasma membrane |
| GO:0031983 | 3.977e-02 | 0.2445 | 3
APP, HGF, VEGFB | 19 | vesicle lumen |
| GO:0060205 | 3.977e-02 | 0.2445 | 3
APP, HGF, VEGFB | 19 | cytoplasmic membrane-bounded vesicle lumen |
| GO:0031226 | 4.060e-02 | 7.128 | 16
ADORA1, APP, BCAM, CD79B, CHRNB2, EPOR, FLRT3, GPR56, ITGAL, KCTD15, LILRB3, RASGRP3, SLC29A1, SLC6A11, STIM1, TGFBR2 | 554 | intrinsic to plasma membrane |
Help |
Hide |
Top
Help |
Show |
Top
GO MF test for over-representation
HELP
List of all enriched GO categories (molecular function), at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module annotated with the given GO term, just by chance.
- Count
is the number of genes in the module annotated with the given GO
term.
- Size is the total number of genes (in our universe)
annotated with the GO term.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
GO category.
Clicking on the GO identifiers takes you to the Gene Ontology web
pages.
— Click on the Help button again to close this help window.
Help |
Hide |
Top
Help |
Show |
Top
KEGG Pathway test for over-representation
HELP
List of all enriched KEGG pathways, at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module annotated with the given KEGG pathway, just by chance.
- Count
is the number of genes in the module annotated with the given KEGG
pathway.
- Size is the total number of genes (in our universe)
annotated with the KEGG pathway.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
KEGG pathway.
Clicking on the KEGG identifiers takes you to the KEGG web site.
— Click on the Help button again to close this help window.
Help |
Hide |
Top
Help |
Show |
Top
miRNA test for over-representation
HELP
List of all enriched miRNA families, at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module regulated by the given miRNA family, just by chance.
- Count
is the number of genes in the module regulated by the given miRNA
family.
- Size is the total number of genes (in our universe)
regulated with the given miRNA family.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
miRNA family.
The miRNA regulation data was taken from the TargetScan database.
(Only the conserved sites were used for the current analysis.)
Clicking on the miRNA names takes you to the TargetScan web site.
— Click on the Help button again to close this help window.
Help |
Hide |
Top
Help |
Show |
Top
Chromosome test for over-representation
HELP
List of all enriched Chromosomes, at the 0.05
p-value level.
The columns:
- ExpCount is the expected number of genes in the
module on the given chromosome, just by chance.
- Count
is the number of genes in the module on the given chromosome.
- Size is the total number of genes (in our universe)
on the given chromosome.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
chromosome.
— Click on the Help button again to close this help window.
HELP
A list of all genes in the current module, in alphabetical order. The
size of the text corresponds to the gene scores.
Note that some gene symbols may show up more than once, if many
probes match the same Entrez gene.
Genes with no Entrez mapping are given separately, with their
Affymetrics probe ID.
— Click on the Help button again to close this help window.
Entrez genes
ABCA7ATP-binding cassette, sub-family A (ABC1), member 7 (219577_s_at), score: -0.85
ABLIM1actin binding LIM protein 1 (200965_s_at), score: 0.69
ADAMTS7ADAM metallopeptidase with thrombospondin type 1 motif, 7 (220705_s_at), score: -0.67
ADORA1adenosine A1 receptor (216220_s_at), score: -0.6
ALDH1L1aldehyde dehydrogenase 1 family, member L1 (215798_at), score: -0.74
APPamyloid beta (A4) precursor protein (214953_s_at), score: -0.61
ARHGAP22Rho GTPase activating protein 22 (206298_at), score: 0.65
ATF5activating transcription factor 5 (204999_s_at), score: 0.65
BAT2HLA-B associated transcript 2 (212081_x_at), score: 0.76
BCAMbasal cell adhesion molecule (Lutheran blood group) (40093_at), score: -0.62
BCL2L1BCL2-like 1 (215037_s_at), score: 0.69
BTNL3butyrophilin-like 3 (217207_s_at), score: -0.68
C13orf34chromosome 13 open reading frame 34 (219544_at), score: 0.75
C19orf61chromosome 19 open reading frame 61 (221335_x_at), score: 0.79
C2orf37chromosome 2 open reading frame 37 (220172_at), score: 0.76
C7orf58chromosome 7 open reading frame 58 (220032_at), score: 0.65
CALB2calbindin 2 (205428_s_at), score: -0.62
CD79BCD79b molecule, immunoglobulin-associated beta (205297_s_at), score: -0.96
CDC42BPBCDC42 binding protein kinase beta (DMPK-like) (217849_s_at), score: 0.73
CDC42EP4CDC42 effector protein (Rho GTPase binding) 4 (214721_x_at), score: 0.67
CHRNB2cholinergic receptor, nicotinic, beta 2 (neuronal) (206635_at), score: -0.67
CITcitron (rho-interacting, serine/threonine kinase 21) (212801_at), score: 0.68
CMAHcytidine monophosphate-N-acetylneuraminic acid hydroxylase (CMP-N-acetylneuraminate monooxygenase) pseudogene (205518_s_at), score: 0.74
CNOT3CCR4-NOT transcription complex, subunit 3 (203239_s_at), score: 0.8
COL11A2collagen, type XI, alpha 2 (216993_s_at), score: -0.68
COX6A2cytochrome c oxidase subunit VIa polypeptide 2 (206353_at), score: -0.63
CYP3A4cytochrome P450, family 3, subfamily A, polypeptide 4 (205998_x_at), score: -0.71
DMBT1deleted in malignant brain tumors 1 (208250_s_at), score: -0.7
EMCNendomucin (219436_s_at), score: 0.88
EPORerythropoietin receptor (215054_at), score: 0.66
ETV7ets variant 7 (221680_s_at), score: -0.66
EVLEnah/Vasp-like (217838_s_at), score: 0.67
EXOC2exocyst complex component 2 (219349_s_at), score: 0.69
FAM105Afamily with sequence similarity 105, member A (219694_at), score: 0.69
FBP1fructose-1,6-bisphosphatase 1 (209696_at), score: -0.77
FBXL14F-box and leucine-rich repeat protein 14 (213145_at), score: 0.7
FBXO2F-box protein 2 (219305_x_at), score: -0.63
FER1L4fer-1-like 4 (C. elegans) (222245_s_at), score: -0.62
FKBP10FK506 binding protein 10, 65 kDa (219249_s_at), score: -0.75
FKRPfukutin related protein (219853_at), score: 0.74
FLRT3fibronectin leucine rich transmembrane protein 3 (219250_s_at), score: 0.74
FUT2fucosyltransferase 2 (secretor status included) (210608_s_at), score: -0.68
GABARAPL1GABA(A) receptor-associated protein like 1 (208868_s_at), score: -0.64
GABARAPL3GABA(A) receptors associated protein like 3 (pseudogene) (211458_s_at), score: -0.67
GBA3glucosidase, beta, acid 3 (cytosolic) (219954_s_at), score: -0.84
GDF9growth differentiation factor 9 (221314_at), score: -0.68
GFOD1glucose-fructose oxidoreductase domain containing 1 (219821_s_at), score: -0.64
GGA3golgi associated, gamma adaptin ear containing, ARF binding protein 3 (209411_s_at), score: 0.67
GPR144G protein-coupled receptor 144 (216289_at), score: -0.68
GPR56G protein-coupled receptor 56 (212070_at), score: 0.69
H1FXH1 histone family, member X (204805_s_at), score: 0.68
HAB1B1 for mucin (215778_x_at), score: -0.8
HAMPhepcidin antimicrobial peptide (220491_at), score: -0.7
HGFhepatocyte growth factor (hepapoietin A; scatter factor) (209960_at), score: 0.73
HIST1H4Dhistone cluster 1, H4d (208076_at), score: -0.61
HIST1H4Ghistone cluster 1, H4g (208551_at), score: -0.74
HMGA1high mobility group AT-hook 1 (210457_x_at), score: 0.81
HSPA4Lheat shock 70kDa protein 4-like (205543_at), score: 0.73
IDUAiduronidase, alpha-L- (205059_s_at), score: 0.74
IRF2interferon regulatory factor 2 (203275_at), score: 0.76
ITGALintegrin, alpha L (antigen CD11A (p180), lymphocyte function-associated antigen 1; alpha polypeptide) (213475_s_at), score: -0.7
JUPjunction plakoglobin (201015_s_at), score: 0.75
KCTD15potassium channel tetramerisation domain containing 15 (218553_s_at), score: -0.69
LILRB3leukocyte immunoglobulin-like receptor, subfamily B (with TM and ITIM domains), member 3 (211133_x_at), score: -0.62
LOC149501similar to keratin 8 (216821_at), score: -0.68
LOC80054hypothetical LOC80054 (220465_at), score: -0.61
LPHN1latrophilin 1 (203488_at), score: -0.67
LRDDleucine-rich repeats and death domain containing (221640_s_at), score: 0.71
MAP3K6mitogen-activated protein kinase kinase kinase 6 (219278_at), score: 0.78
MDM2Mdm2 p53 binding protein homolog (mouse) (205386_s_at), score: 0.7
MEOX1mesenchyme homeobox 1 (205619_s_at), score: -0.77
MOBPmyelin-associated oligodendrocyte basic protein (210193_at), score: -0.77
MOCS1molybdenum cofactor synthesis 1 (211673_s_at), score: -0.71
MOGmyelin oligodendrocyte glycoprotein (214650_x_at), score: -0.69
MRPS6mitochondrial ribosomal protein S6 (213167_s_at), score: 0.8
MTMR11myotubularin related protein 11 (205076_s_at), score: 0.82
MUC5ACmucin 5AC, oligomeric mucus/gel-forming (217182_at), score: -0.69
NDPNorrie disease (pseudoglioma) (206022_at), score: 0.86
NF1neurofibromin 1 (211094_s_at), score: 0.84
NFYCnuclear transcription factor Y, gamma (202215_s_at), score: 0.67
NOVA2neuro-oncological ventral antigen 2 (206477_s_at), score: -0.64
NUPL2nucleoporin like 2 (204003_s_at), score: -0.62
NXPH3neurexophilin 3 (221991_at), score: -0.72
OAS32'-5'-oligoadenylate synthetase 3, 100kDa (218400_at), score: 0.73
OLFML2Bolfactomedin-like 2B (213125_at), score: 1
OR7E47Polfactory receptor, family 7, subfamily E, member 47 pseudogene (216698_x_at), score: -0.68
PAK1p21 protein (Cdc42/Rac)-activated kinase 1 (209615_s_at), score: 0.9
PARVBparvin, beta (204629_at), score: 0.68
PDE5Aphosphodiesterase 5A, cGMP-specific (206757_at), score: 0.79
PHF7PHD finger protein 7 (215622_x_at), score: -0.66
PNMAL1PNMA-like 1 (218824_at), score: 0.68
PRLHprolactin releasing hormone (221443_x_at), score: -0.72
PTPN6protein tyrosine phosphatase, non-receptor type 6 (206687_s_at), score: -0.93
PXNpaxillin (211823_s_at), score: 0.9
RASGRP3RAS guanyl releasing protein 3 (calcium and DAG-regulated) (205801_s_at), score: 0.75
REG3Aregenerating islet-derived 3 alpha (205815_at), score: -0.72
RNF220ring finger protein 220 (219988_s_at), score: 0.68
RP4-691N24.1ninein-like (207705_s_at), score: 0.7
RPL18AP6ribosomal protein L18a pseudogene 6 (216383_at), score: -0.71
RPRD2regulation of nuclear pre-mRNA domain containing 2 (212553_at), score: 0.69
RPS17P5ribosomal protein S17 pseudogene 5 (216348_at), score: -0.61
SAA4serum amyloid A4, constitutive (207096_at), score: -0.63
SCAMP4secretory carrier membrane protein 4 (213244_at), score: 0.78
SDPRserum deprivation response (phosphatidylserine binding protein) (218711_s_at), score: 0.77
SEC61A2Sec61 alpha 2 subunit (S. cerevisiae) (219499_at), score: 0.8
SEMA3Fsema domain, immunoglobulin domain (Ig), short basic domain, secreted, (semaphorin) 3F (35666_at), score: -0.62
SENP7SUMO1/sentrin specific peptidase 7 (220735_s_at), score: 0.66
SIRT6sirtuin (silent mating type information regulation 2 homolog) 6 (S. cerevisiae) (219613_s_at), score: 0.66
SLC26A10solute carrier family 26, member 10 (214951_at), score: -0.71
SLC29A1solute carrier family 29 (nucleoside transporters), member 1 (201801_s_at), score: 0.75
SLC5A5solute carrier family 5 (sodium iodide symporter), member 5 (211123_at), score: -0.72
SLC6A11solute carrier family 6 (neurotransmitter transporter, GABA), member 11 (207048_at), score: -0.69
SOLHsmall optic lobes homolog (Drosophila) (204275_at), score: 0.69
SPATA1spermatogenesis associated 1 (221057_at), score: -0.75
SSX3synovial sarcoma, X breakpoint 3 (211731_x_at), score: -0.65
STIM1stromal interaction molecule 1 (202764_at), score: 0.77
SULT1B1sulfotransferase family, cytosolic, 1B, member 1 (207601_at), score: -0.7
TGFBR2transforming growth factor, beta receptor II (70/80kDa) (207334_s_at), score: 0.76
TGIF2TGFB-induced factor homeobox 2 (216262_s_at), score: -0.66
TGM4transglutaminase 4 (prostate) (217566_s_at), score: -0.71
TMSB4Ythymosin beta 4, Y-linked (206769_at), score: -0.68
TRAF5TNF receptor-associated factor 5 (204352_at), score: -0.62
TULP2tubby like protein 2 (206733_at), score: -0.78
UBTD1ubiquitin domain containing 1 (219172_at), score: 0.77
VEGFBvascular endothelial growth factor B (203683_s_at), score: 0.85
ZNF281zinc finger protein 281 (218401_s_at), score: -0.62
Non-Entrez genes
Unknown, score:
HELP
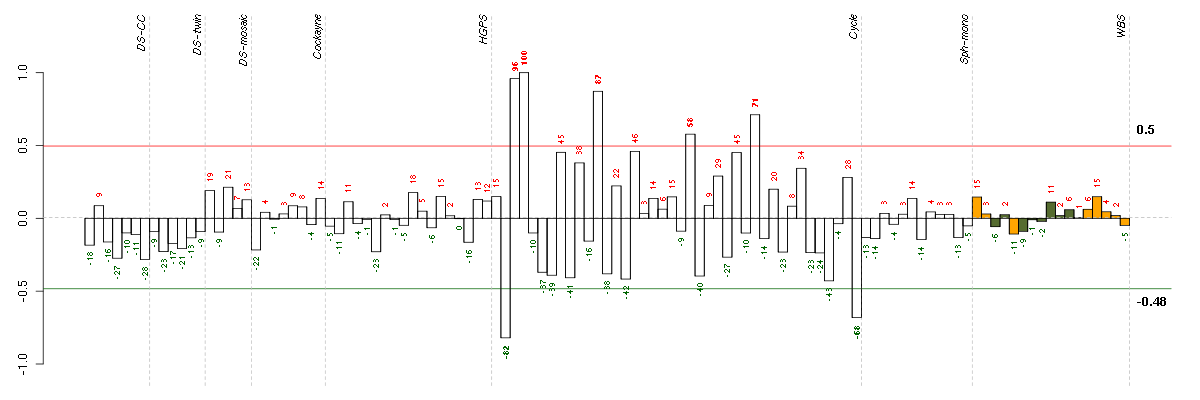
Conditions in the module, given in the same order as on the expression
plot above. Red color means over-expression, green under-expression in
the given condition.
The barplot below shows the condition (sample) scores. A separate bar
is shown for each sample, its height is the corresponding score of the
sample in the module. The red and green numbers on the bars are the
sample scores expressed in percents, i.e. 100% is 1.0.
The red and green lines show the module thresholds, samples above
the red line and below the green line are included in the module.
The different experiments that were part of the study, are separated
by dashed vertical lines.
— Click on the Help button again to close this help window.
| Id | sample | Experiment | ExpName | Array | Syndrome | Cell.line |
| E-TABM-263-raw-cel-1515485671.cel | 2 | 6 | Cycle | hgu133a2 | none | Cycle 1 |
| E-TABM-263-raw-cel-1515486431.cel | 40 | 6 | Cycle | hgu133a2 | none | Cycle 1 |
| E-TABM-263-raw-cel-1515486071.cel | 22 | 6 | Cycle | hgu133a2 | none | Cycle 1 |
| E-TABM-263-raw-cel-1515486211.cel | 29 | 6 | Cycle | hgu133a2 | none | Cycle 1 |
| E-TABM-263-raw-cel-1515485871.cel | 12 | 6 | Cycle | hgu133a2 | none | Cycle 1 |
| E-TABM-263-raw-cel-1515485691.cel | 3 | 6 | Cycle | hgu133a2 | none | Cycle 1 |
| E-TABM-263-raw-cel-1515485711.cel | 4 | 6 | Cycle | hgu133a2 | none | Cycle 1 |



© 2008-2010 Computational Biology Group, Department of Medical Genetics,
University of Lausanne, Switzerland