Previous module |
Next module
Module #754, TG: 2.6, TC: 1.6, 95 probes, 95 Entrez genes, 10 conditions


HELP
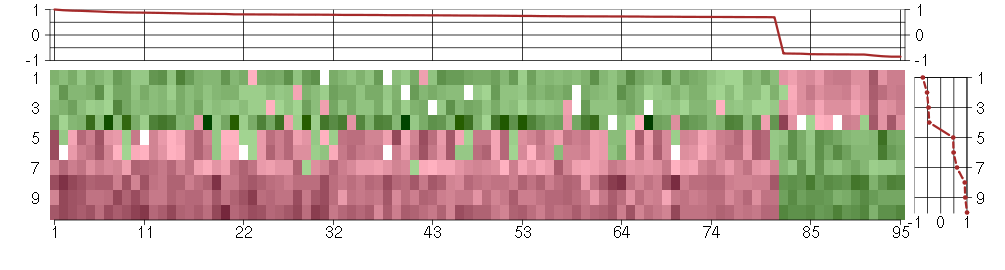
The image plot shows the color-coded level of gene expression, for the
genes and conditions in a given transcription module. The genes are on
the horizontal, the conditions on the vertical axis.
The genes are ordered according to their ISA gene scores, similarly
the conditions are ordered according to their condition scores. The
score of a gene means the «degree of inclusion» in
the module: a high score gene is essential in the module.
Condition scores can also be negative, that means that the genes of
the module are all down-regulated in the condition. Here the absolute
value of the score gives the «degree of inclusion».
The plots above and beside the expression matrix show the gene scores
and condition scores, respectively.
Note that the plot is interactive, you can see the name of the gene
and condition under the mouse cursor.
The expression matrix was normalized to have mean zero and standard
deviation one for every gene separately across all conditions
(i.e. not just for the conditions in the module).
— Click on the Help button again to close this help window.

Under-expression is coded with green,
over-expression with red color.
Help |
Hide |
Top
Help |
Show |
Top
The GO tree — Biological processes
HELP
This is one of three sections showing Gene Ontology enrichment of the
current module: in this case for biological processes.
The graph shows the hierarchy of the GO categories, their enrichment
for the current module is color coded, and the blue number beside the
category is the minus log ten p-value of the enrichment. (Calculated
using the standard hypergeometric test.) The color of the arrows code
«is a» (cyan) and «part of» relationships.
The tree was built the following way. First all GO terms with more
significant enrichment p-value than 0.05 were collected. Then all
paths from these terms to the root node of the GO tree were included
too. If a GO term is included more than once in the tree, then the
green numbers show 1) the id of the node, this makes it easier to find
other appereances of the term, and 2) the number of appearences.
Note that the same GO category might show up on the graph many
times. This is because the GO was «straightened» for this
graph, i.e. if there are more paths from a GO term to the root node of
the tree, all of them are included. The green numbers
Move the mouse cursor over the terms to get their definition. Clicking
on them takes you to the corresponding Gene Ontology web page.
If you cannot see a graph here at all, that means that there were no
significantly enriched GO categories, at the 0.05 level.
— Click on the Help button again to close this help window.

Help |
Hide |
Top
Help |
Show |
Top
The GO tree — Cellular Components
HELP
This is one of three sections showing Gene Ontology enrichment of the
current module: in this case for cellular components.
The graph shows the hierarchy of the GO categories, their enrichment
for the current module is color coded, and the blue number beside the
category is the minus log ten p-value of the enrichment. (Calculated
using the standard hypergeometric test.) The color of the arrows code
«is a» (cyan) and «part of» relationships.
The tree was built the following way. First all GO terms with more
significant enrichment p-value than 0.05 were collected. Then all
paths from these terms to the root node of the GO tree were included
too. If a GO term is included more than once in the tree, then the
green numbers show 1) the id of the node, this makes it easier to find
other appereances of the term, and 2) the number of appearences.
Note that the same GO category might show up on the graph many
times. This is because the GO was «straightened» for this
graph, i.e. if there are more paths from a GO term to the root node of
the tree, all of them are included. The green numbers
Move the mouse cursor over the terms to get their definition. Clicking
on them takes you to the corresponding Gene Ontology web page.
If you cannot see a graph here at all, that means that there were no
significantly enriched GO categories, at the 0.05 level.
— Click on the Help button again to close this help window.
Help |
Hide |
Top
Help |
Show |
Top
The GO tree — Molecular Function
HELP
This is one of three sections showing Gene Ontology enrichment of the
current module: in this case for molecular function.
The graph shows the hierarchy of the GO categories, their enrichment
for the current module is color coded, and the blue number beside the
category is the minus log ten p-value of the enrichment. (Calculated
using the standard hypergeometric test.) The color of the arrows code
«is a» (cyan) and «part of» relationships.
The tree was built the following way. First all GO terms with more
significant enrichment p-value than 0.05 were collected. Then all
paths from these terms to the root node of the GO tree were included
too. If a GO term is included more than once in the tree, then the
green numbers show 1) the id of the node, this makes it easier to find
other appereances of the term, and 2) the number of appearences.
Note that the same GO category might show up on the graph many
times. This is because the GO was «straightened» for this
graph, i.e. if there are more paths from a GO term to the root node of
the tree, all of them are included. The green numbers
Move the mouse cursor over the terms to get their definition. Clicking
on them takes you to the corresponding Gene Ontology web page.
If you cannot see a graph here at all, that means that there were no
significantly enriched GO categories, at the 0.05 level.
— Click on the Help button again to close this help window.
Help |
Hide |
Top
Help |
Show |
Top
GO BP test for over-representation
HELP
List of all enriched GO categories (biological processes), at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module annotated with the given GO term, just by chance.
- Count
is the number of genes in the module annotated with the given GO
term.
- Size is the total number of genes (in our universe)
annotated with the GO term.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
GO category.
Clicking on the GO identifiers takes you to the Gene Ontology web
pages.
— Click on the Help button again to close this help window.
| Id | Pvalue | ExpCount | Count | Size | Term |
| GO:0043555 | 1.634e-02 | 0.02508 | 2
EIF2AK3, EIF2S1 | 3 | regulation of translation in response to stress |
| GO:0043558 | 1.634e-02 | 0.02508 | 2
EIF2AK3, EIF2S1 | 3 | regulation of translational initiation in response to stress |
Help |
Hide |
Top
Help |
Show |
Top
GO CC test for over-representation
HELP
List of all enriched GO categories (cellular components), at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module annotated with the given GO term, just by chance.
- Count
is the number of genes in the module annotated with the given GO
term.
- Size is the total number of genes (in our universe)
annotated with the GO term.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
GO category.
Clicking on the GO identifiers takes you to the Gene Ontology web
pages.
— Click on the Help button again to close this help window.
| Id | Pvalue | ExpCount | Count | Size | Term |
| GO:0031968 | 1.352e-02 | 0.6539 | 5
ACSL1, ACSL4, OPA1, SYNE1, TOMM20 | 72 | organelle outer membrane |
| GO:0019867 | 1.511e-02 | 0.672 | 5
ACSL1, ACSL4, OPA1, SYNE1, TOMM20 | 74 | outer membrane |
| GO:0005741 | 4.623e-02 | 0.5449 | 4
ACSL1, ACSL4, OPA1, TOMM20 | 60 | mitochondrial outer membrane |
Help |
Hide |
Top
Help |
Show |
Top
GO MF test for over-representation
HELP
List of all enriched GO categories (molecular function), at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module annotated with the given GO term, just by chance.
- Count
is the number of genes in the module annotated with the given GO
term.
- Size is the total number of genes (in our universe)
annotated with the GO term.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
GO category.
Clicking on the GO identifiers takes you to the Gene Ontology web
pages.
— Click on the Help button again to close this help window.
Help |
Hide |
Top
Help |
Show |
Top
KEGG Pathway test for over-representation
HELP
List of all enriched KEGG pathways, at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module annotated with the given KEGG pathway, just by chance.
- Count
is the number of genes in the module annotated with the given KEGG
pathway.
- Size is the total number of genes (in our universe)
annotated with the KEGG pathway.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
KEGG pathway.
Clicking on the KEGG identifiers takes you to the KEGG web site.
— Click on the Help button again to close this help window.
Help |
Hide |
Top
Help |
Show |
Top
miRNA test for over-representation
HELP
List of all enriched miRNA families, at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module regulated by the given miRNA family, just by chance.
- Count
is the number of genes in the module regulated by the given miRNA
family.
- Size is the total number of genes (in our universe)
regulated with the given miRNA family.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
miRNA family.
The miRNA regulation data was taken from the TargetScan database.
(Only the conserved sites were used for the current analysis.)
Clicking on the miRNA names takes you to the TargetScan web site.
— Click on the Help button again to close this help window.
Help |
Hide |
Top
Help |
Show |
Top
Chromosome test for over-representation
HELP
List of all enriched Chromosomes, at the 0.05
p-value level.
The columns:
- ExpCount is the expected number of genes in the
module on the given chromosome, just by chance.
- Count
is the number of genes in the module on the given chromosome.
- Size is the total number of genes (in our universe)
on the given chromosome.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
chromosome.
— Click on the Help button again to close this help window.
HELP
A list of all genes in the current module, in alphabetical order. The
size of the text corresponds to the gene scores.
Note that some gene symbols may show up more than once, if many
probes match the same Entrez gene.
Genes with no Entrez mapping are given separately, with their
Affymetrics probe ID.
— Click on the Help button again to close this help window.
Entrez genes
ABCE1ATP-binding cassette, sub-family E (OABP), member 1 (201873_s_at), score: 0.8
ACSL1acyl-CoA synthetase long-chain family member 1 (201963_at), score: 0.79
ACSL4acyl-CoA synthetase long-chain family member 4 (202422_s_at), score: 0.82
ACTR3BARP3 actin-related protein 3 homolog B (yeast) (218868_at), score: 0.95
ADORA2Badenosine A2b receptor (205891_at), score: -0.77
AHI1Abelson helper integration site 1 (221569_at), score: 0.78
AIM1absent in melanoma 1 (212543_at), score: -0.77
ATP2C1ATPase, Ca++ transporting, type 2C, member 1 (211137_s_at), score: 0.71
BMP6bone morphogenetic protein 6 (206176_at), score: 0.72
C14orf138chromosome 14 open reading frame 138 (218940_at), score: 0.71
C14orf45chromosome 14 open reading frame 45 (220173_at), score: 0.74
C14orf94chromosome 14 open reading frame 94 (218383_at), score: -0.85
C4orf43chromosome 4 open reading frame 43 (218513_at), score: 0.8
C5orf44chromosome 5 open reading frame 44 (218674_at), score: 0.76
C7orf64chromosome 7 open reading frame 64 (221596_s_at), score: 0.76
CALB2calbindin 2 (205428_s_at), score: 0.79
CASC3cancer susceptibility candidate 3 (207842_s_at), score: -0.76
CDC25Bcell division cycle 25 homolog B (S. pombe) (201853_s_at), score: -0.85
CDC2L6cell division cycle 2-like 6 (CDK8-like) (212899_at), score: -0.76
CDH6cadherin 6, type 2, K-cadherin (fetal kidney) (205532_s_at), score: 0.71
CHORDC1cysteine and histidine-rich domain (CHORD)-containing 1 (218566_s_at), score: 0.72
CHUKconserved helix-loop-helix ubiquitous kinase (209666_s_at), score: 0.75
CITcitron (rho-interacting, serine/threonine kinase 21) (212801_at), score: -0.76
CMPK1cytidine monophosphate (UMP-CMP) kinase 1, cytosolic (217870_s_at), score: 0.8
CSGALNACT2chondroitin sulfate N-acetylgalactosaminyltransferase 2 (222235_s_at), score: 0.77
DENND5BDENN/MADD domain containing 5B (215058_at), score: 0.88
DIS3DIS3 mitotic control homolog (S. cerevisiae) (218362_s_at), score: 0.73
DNAJB9DnaJ (Hsp40) homolog, subfamily B, member 9 (202843_at), score: 0.95
DOCK9dedicator of cytokinesis 9 (212538_at), score: 0.72
DOPEY1dopey family member 1 (40612_at), score: 0.76
EAF2ELL associated factor 2 (219551_at), score: 0.8
EDEM1ER degradation enhancer, mannosidase alpha-like 1 (203279_at), score: 0.79
EIF2AK3eukaryotic translation initiation factor 2-alpha kinase 3 (218696_at), score: 0.73
EIF2S1eukaryotic translation initiation factor 2, subunit 1 alpha, 35kDa (201143_s_at), score: 0.7
EIF4Eeukaryotic translation initiation factor 4E (201436_at), score: 0.81
FAM18Bfamily with sequence similarity 18, member B (218446_s_at), score: 0.87
FAM3Cfamily with sequence similarity 3, member C (201889_at), score: 0.72
FAM8A1family with sequence similarity 8, member A1 (203420_at), score: 0.71
GFOD1glucose-fructose oxidoreductase domain containing 1 (219821_s_at), score: 0.89
GHRgrowth hormone receptor (205498_at), score: 0.81
GK3Pglycerol kinase 3 pseudogene (215966_x_at), score: 0.82
GMCL1germ cell-less homolog 1 (Drosophila) (218458_at), score: 0.8
H1F0H1 histone family, member 0 (208886_at), score: -0.83
H1FXH1 histone family, member X (204805_s_at), score: -0.75
HISPPD1histidine acid phosphatase domain containing 1 (203253_s_at), score: 0.78
HSD17B6hydroxysteroid (17-beta) dehydrogenase 6 homolog (mouse) (37512_at), score: 0.75
KAL1Kallmann syndrome 1 sequence (205206_at), score: 0.97
KIAA0562KIAA0562 (204075_s_at), score: 0.79
LARP4La ribonucleoprotein domain family, member 4 (214155_s_at), score: 0.93
LOC391132similar to hCG2041276 (216177_at), score: 0.72
LPGAT1lysophosphatidylglycerol acyltransferase 1 (202651_at), score: 0.78
LRP8low density lipoprotein receptor-related protein 8, apolipoprotein e receptor (205282_at), score: 0.7
MFAP3microfibrillar-associated protein 3 (213123_at), score: 0.77
MFAP3Lmicrofibrillar-associated protein 3-like (205442_at), score: 0.86
NARG1LNMDA receptor regulated 1-like (219378_at), score: 0.73
NEFMneurofilament, medium polypeptide (205113_at), score: 0.81
NOX4NADPH oxidase 4 (219773_at), score: 0.73
OPA1optic atrophy 1 (autosomal dominant) (212213_x_at), score: 0.75
OSTM1osteopetrosis associated transmembrane protein 1 (218196_at), score: 0.84
PAK1p21 protein (Cdc42/Rac)-activated kinase 1 (209615_s_at), score: -0.8
PCDH9protocadherin 9 (219737_s_at), score: 0.88
PRMT3protein arginine methyltransferase 3 (213320_at), score: 0.85
RAB1ARAB1A, member RAS oncogene family (213440_at), score: 0.81
RAB7ARAB7A, member RAS oncogene family (211960_s_at), score: 0.7
RANBP6RAN binding protein 6 (213019_at), score: 0.71
RNF11ring finger protein 11 (208924_at), score: 0.8
RP5-1000E10.4suppressor of IKK epsilon (221705_s_at), score: 0.79
RRP15ribosomal RNA processing 15 homolog (S. cerevisiae) (219037_at), score: 0.76
SLC25A32solute carrier family 25, member 32 (221020_s_at), score: 0.77
SLC33A1solute carrier family 33 (acetyl-CoA transporter), member 1 (203165_s_at), score: 0.73
SLC43A3solute carrier family 43, member 3 (213113_s_at), score: -0.76
SLC4A7solute carrier family 4, sodium bicarbonate cotransporter, member 7 (209884_s_at), score: 0.88
SLMO2slowmo homolog 2 (Drosophila) (217851_s_at), score: 0.9
SYNE1spectrin repeat containing, nuclear envelope 1 (209447_at), score: 0.7
SYNJ1synaptojanin 1 (212990_at), score: 0.81
TAF2TAF2 RNA polymerase II, TATA box binding protein (TBP)-associated factor, 150kDa (209523_at), score: 0.73
TASP1taspase, threonine aspartase, 1 (219443_at), score: 0.74
TCEB1transcription elongation factor B (SIII), polypeptide 1 (15kDa, elongin C) (202823_at), score: 0.73
TGDSTDP-glucose 4,6-dehydratase (208249_s_at), score: 1
TICAM2toll-like receptor adaptor molecule 2 (214658_at), score: 0.87
TMF1TATA element modulatory factor 1 (213024_at), score: 0.75
TOMM20translocase of outer mitochondrial membrane 20 homolog (yeast) (200662_s_at), score: 0.83
TPBGtrophoblast glycoprotein (203476_at), score: -0.73
TRAPPC2trafficking protein particle complex 2 (219351_at), score: 0.72
TRIM21tripartite motif-containing 21 (204804_at), score: -0.72
TRMT2ATRM2 tRNA methyltransferase 2 homolog A (S. cerevisiae) (91617_at), score: 0.78
UBE2Wubiquitin-conjugating enzyme E2W (putative) (218521_s_at), score: 0.76
UFM1ubiquitin-fold modifier 1 (218050_at), score: 0.83
UHRF1BP1LUHRF1 binding protein 1-like (213118_at), score: 0.7
WDR6WD repeat domain 6 (217734_s_at), score: -0.73
WHAMML1WAS protein homolog associated with actin, golgi membranes and microtubules-like 1 (213908_at), score: 0.77
YTHDC2YTH domain containing 2 (213077_at), score: 0.74
ZCCHC10zinc finger, CCHC domain containing 10 (221193_s_at), score: 0.71
ZNF23zinc finger protein 23 (KOX 16) (213934_s_at), score: 0.92
ZNF652zinc finger protein 652 (205594_at), score: 0.77
Non-Entrez genes
Unknown, score:
HELP
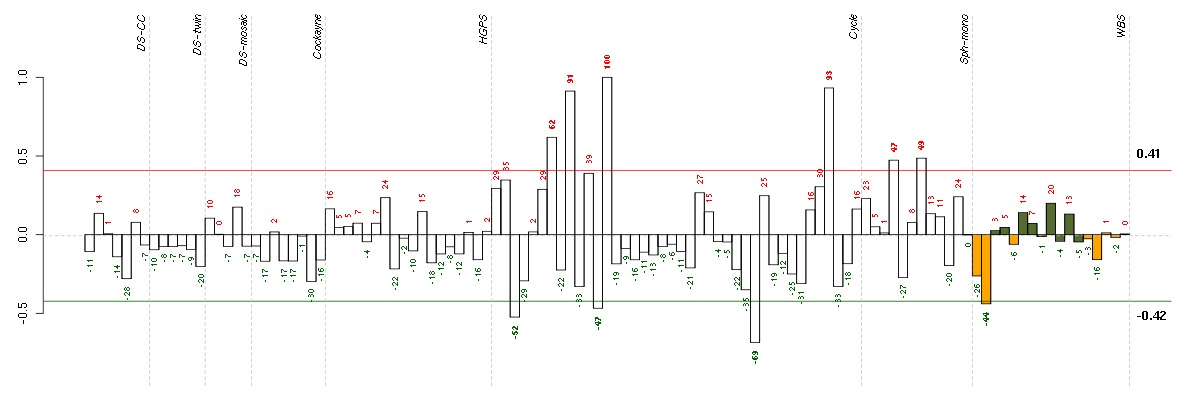
Conditions in the module, given in the same order as on the expression
plot above. Red color means over-expression, green under-expression in
the given condition.
The barplot below shows the condition (sample) scores. A separate bar
is shown for each sample, its height is the corresponding score of the
sample in the module. The red and green numbers on the bars are the
sample scores expressed in percents, i.e. 100% is 1.0.
The red and green lines show the module thresholds, samples above
the red line and below the green line are included in the module.
The different experiments that were part of the study, are separated
by dashed vertical lines.
— Click on the Help button again to close this help window.
| Id | sample | Experiment | ExpName | Array | Syndrome | Cell.line |
| E-TABM-263-raw-cel-1515486211.cel | 29 | 6 | Cycle | hgu133a2 | none | Cycle 1 |
| E-TABM-263-raw-cel-1515485691.cel | 3 | 6 | Cycle | hgu133a2 | none | Cycle 1 |
| E-TABM-263-raw-cel-1515485871.cel | 12 | 6 | Cycle | hgu133a2 | none | Cycle 1 |
| 10590_WBS.CEL | 2 | 8 | WBS | hgu133plus2 | WBS | WBS 1 |
| E-GEOD-4219-raw-cel-1311956275.cel | 8 | 7 | Sph-mono | hgu133plus2 | none | Sph-mon 1 |
| E-GEOD-4219-raw-cel-1311956398.cel | 12 | 7 | Sph-mono | hgu133plus2 | none | Sph-mon 1 |
| E-TABM-263-raw-cel-1515485771.cel | 7 | 6 | Cycle | hgu133a2 | none | Cycle 1 |
| E-TABM-263-raw-cel-1515485811.cel | 9 | 6 | Cycle | hgu133a2 | none | Cycle 1 |
| E-TABM-263-raw-cel-1515486371.cel | 37 | 6 | Cycle | hgu133a2 | none | Cycle 1 |
| E-TABM-263-raw-cel-1515485891.cel | 13 | 6 | Cycle | hgu133a2 | none | Cycle 1 |



© 2008-2010 Computational Biology Group, Department of Medical Genetics,
University of Lausanne, Switzerland