Previous module |
Next module
Module #710, TG: 2.6, TC: 2, 105 probes, 105 Entrez genes, 4 conditions


HELP
The image plot shows the color-coded level of gene expression, for the
genes and conditions in a given transcription module. The genes are on
the horizontal, the conditions on the vertical axis.
The genes are ordered according to their ISA gene scores, similarly
the conditions are ordered according to their condition scores. The
score of a gene means the «degree of inclusion» in
the module: a high score gene is essential in the module.
Condition scores can also be negative, that means that the genes of
the module are all down-regulated in the condition. Here the absolute
value of the score gives the «degree of inclusion».
The plots above and beside the expression matrix show the gene scores
and condition scores, respectively.
Note that the plot is interactive, you can see the name of the gene
and condition under the mouse cursor.
The expression matrix was normalized to have mean zero and standard
deviation one for every gene separately across all conditions
(i.e. not just for the conditions in the module).
— Click on the Help button again to close this help window.

Under-expression is coded with green,
over-expression with red color.
Help |
Hide |
Top
Help |
Show |
Top
The GO tree — Biological processes
HELP
This is one of three sections showing Gene Ontology enrichment of the
current module: in this case for biological processes.
The graph shows the hierarchy of the GO categories, their enrichment
for the current module is color coded, and the blue number beside the
category is the minus log ten p-value of the enrichment. (Calculated
using the standard hypergeometric test.) The color of the arrows code
«is a» (cyan) and «part of» relationships.
The tree was built the following way. First all GO terms with more
significant enrichment p-value than 0.05 were collected. Then all
paths from these terms to the root node of the GO tree were included
too. If a GO term is included more than once in the tree, then the
green numbers show 1) the id of the node, this makes it easier to find
other appereances of the term, and 2) the number of appearences.
Note that the same GO category might show up on the graph many
times. This is because the GO was «straightened» for this
graph, i.e. if there are more paths from a GO term to the root node of
the tree, all of them are included. The green numbers
Move the mouse cursor over the terms to get their definition. Clicking
on them takes you to the corresponding Gene Ontology web page.
If you cannot see a graph here at all, that means that there were no
significantly enriched GO categories, at the 0.05 level.
— Click on the Help button again to close this help window.

Help |
Hide |
Top
Help |
Show |
Top
The GO tree — Cellular Components
HELP
This is one of three sections showing Gene Ontology enrichment of the
current module: in this case for cellular components.
The graph shows the hierarchy of the GO categories, their enrichment
for the current module is color coded, and the blue number beside the
category is the minus log ten p-value of the enrichment. (Calculated
using the standard hypergeometric test.) The color of the arrows code
«is a» (cyan) and «part of» relationships.
The tree was built the following way. First all GO terms with more
significant enrichment p-value than 0.05 were collected. Then all
paths from these terms to the root node of the GO tree were included
too. If a GO term is included more than once in the tree, then the
green numbers show 1) the id of the node, this makes it easier to find
other appereances of the term, and 2) the number of appearences.
Note that the same GO category might show up on the graph many
times. This is because the GO was «straightened» for this
graph, i.e. if there are more paths from a GO term to the root node of
the tree, all of them are included. The green numbers
Move the mouse cursor over the terms to get their definition. Clicking
on them takes you to the corresponding Gene Ontology web page.
If you cannot see a graph here at all, that means that there were no
significantly enriched GO categories, at the 0.05 level.
— Click on the Help button again to close this help window.
Help |
Hide |
Top
Help |
Show |
Top
The GO tree — Molecular Function
HELP
This is one of three sections showing Gene Ontology enrichment of the
current module: in this case for molecular function.
The graph shows the hierarchy of the GO categories, their enrichment
for the current module is color coded, and the blue number beside the
category is the minus log ten p-value of the enrichment. (Calculated
using the standard hypergeometric test.) The color of the arrows code
«is a» (cyan) and «part of» relationships.
The tree was built the following way. First all GO terms with more
significant enrichment p-value than 0.05 were collected. Then all
paths from these terms to the root node of the GO tree were included
too. If a GO term is included more than once in the tree, then the
green numbers show 1) the id of the node, this makes it easier to find
other appereances of the term, and 2) the number of appearences.
Note that the same GO category might show up on the graph many
times. This is because the GO was «straightened» for this
graph, i.e. if there are more paths from a GO term to the root node of
the tree, all of them are included. The green numbers
Move the mouse cursor over the terms to get their definition. Clicking
on them takes you to the corresponding Gene Ontology web page.
If you cannot see a graph here at all, that means that there were no
significantly enriched GO categories, at the 0.05 level.
— Click on the Help button again to close this help window.
Help |
Hide |
Top
Help |
Show |
Top
GO BP test for over-representation
HELP
List of all enriched GO categories (biological processes), at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module annotated with the given GO term, just by chance.
- Count
is the number of genes in the module annotated with the given GO
term.
- Size is the total number of genes (in our universe)
annotated with the GO term.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
GO category.
Clicking on the GO identifiers takes you to the Gene Ontology web
pages.
— Click on the Help button again to close this help window.
| Id | Pvalue | ExpCount | Count | Size | Term |
| GO:0008298 | 2.318e-02 | 0.03166 | 2
CASC3, STAU1 | 3 | intracellular mRNA localization |
| GO:0006403 | 4.926e-02 | 0.7704 | 5
CASC3, NPIP, POM121, SMG7, STAU1 | 73 | RNA localization |
Help |
Hide |
Top
Help |
Show |
Top
GO CC test for over-representation
HELP
List of all enriched GO categories (cellular components), at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module annotated with the given GO term, just by chance.
- Count
is the number of genes in the module annotated with the given GO
term.
- Size is the total number of genes (in our universe)
annotated with the GO term.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
GO category.
Clicking on the GO identifiers takes you to the Gene Ontology web
pages.
— Click on the Help button again to close this help window.
Help |
Hide |
Top
Help |
Show |
Top
GO MF test for over-representation
HELP
List of all enriched GO categories (molecular function), at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module annotated with the given GO term, just by chance.
- Count
is the number of genes in the module annotated with the given GO
term.
- Size is the total number of genes (in our universe)
annotated with the GO term.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
GO category.
Clicking on the GO identifiers takes you to the Gene Ontology web
pages.
— Click on the Help button again to close this help window.
Help |
Hide |
Top
Help |
Show |
Top
KEGG Pathway test for over-representation
HELP
List of all enriched KEGG pathways, at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module annotated with the given KEGG pathway, just by chance.
- Count
is the number of genes in the module annotated with the given KEGG
pathway.
- Size is the total number of genes (in our universe)
annotated with the KEGG pathway.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
KEGG pathway.
Clicking on the KEGG identifiers takes you to the KEGG web site.
— Click on the Help button again to close this help window.
Help |
Hide |
Top
Help |
Show |
Top
miRNA test for over-representation
HELP
List of all enriched miRNA families, at the 0.05
p-value level.
The columns:
- ExpCount is the expected count of genes in the
module regulated by the given miRNA family, just by chance.
- Count
is the number of genes in the module regulated by the given miRNA
family.
- Size is the total number of genes (in our universe)
regulated with the given miRNA family.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
miRNA family.
The miRNA regulation data was taken from the TargetScan database.
(Only the conserved sites were used for the current analysis.)
Clicking on the miRNA names takes you to the TargetScan web site.
— Click on the Help button again to close this help window.
Help |
Hide |
Top
Help |
Show |
Top
Chromosome test for over-representation
HELP
List of all enriched Chromosomes, at the 0.05
p-value level.
The columns:
- ExpCount is the expected number of genes in the
module on the given chromosome, just by chance.
- Count
is the number of genes in the module on the given chromosome.
- Size is the total number of genes (in our universe)
on the given chromosome.
Clicking on Count shows the genes that drive the
enrichment. You can also click on the individual numbers in
the Count column, to show the driving genes for that individual
chromosome.
— Click on the Help button again to close this help window.
HELP
A list of all genes in the current module, in alphabetical order. The
size of the text corresponds to the gene scores.
Note that some gene symbols may show up more than once, if many
probes match the same Entrez gene.
Genes with no Entrez mapping are given separately, with their
Affymetrics probe ID.
— Click on the Help button again to close this help window.
Entrez genes
ADCY3adenylate cyclase 3 (209321_s_at), score: -0.98
AKAP2A kinase (PRKA) anchor protein 2 (202759_s_at), score: -0.64
ANAPC2anaphase promoting complex subunit 2 (218555_at), score: -0.6
ARNTLaryl hydrocarbon receptor nuclear translocator-like (209824_s_at), score: -0.6
BIN1bridging integrator 1 (210201_x_at), score: -0.8
BRCA2breast cancer 2, early onset (208368_s_at), score: 0.79
BTBD2BTB (POZ) domain containing 2 (207722_s_at), score: -0.62
C14orf106chromosome 14 open reading frame 106 (206500_s_at), score: 0.7
C9orf9chromosome 9 open reading frame 9 (220050_at), score: -0.61
CASC3cancer susceptibility candidate 3 (207842_s_at), score: -0.63
CDC42BPBCDC42 binding protein kinase beta (DMPK-like) (217849_s_at), score: -0.66
CDR2Lcerebellar degeneration-related protein 2-like (213230_at), score: -0.7
CENPQcentromere protein Q (219294_at), score: 0.69
CEP192centrosomal protein 192kDa (218827_s_at), score: 0.67
CHST2carbohydrate (N-acetylglucosamine-6-O) sulfotransferase 2 (203921_at), score: -0.72
CNOT3CCR4-NOT transcription complex, subunit 3 (203239_s_at), score: -0.6
COL10A1collagen, type X, alpha 1 (217428_s_at), score: -0.73
CORO2Bcoronin, actin binding protein, 2B (209789_at), score: -0.62
CROPcisplatin resistance-associated overexpressed protein (208835_s_at), score: 0.67
CRTC3CREB regulated transcription coactivator 3 (218648_at), score: -0.73
DENND4BDENN/MADD domain containing 4B (202860_at), score: -0.79
DKFZP586I1420hypothetical protein DKFZp586I1420 (213546_at), score: 0.67
DMPKdystrophia myotonica-protein kinase (37996_s_at), score: -0.64
DNA2DNA replication helicase 2 homolog (yeast) (213647_at), score: 0.71
DOK4docking protein 4 (209691_s_at), score: -0.6
E2F8E2F transcription factor 8 (219990_at), score: 0.68
EML2echinoderm microtubule associated protein like 2 (204398_s_at), score: 0.67
EPHA4EPH receptor A4 (206114_at), score: 0.75
FASNfatty acid synthase (212218_s_at), score: -0.71
FBXO17F-box protein 17 (220233_at), score: -0.61
FKBPLFK506 binding protein like (219187_at), score: 0.74
FKRPfukutin related protein (219853_at), score: -0.65
FLJ12529pre-mRNA cleavage factor I, 59 kDa subunit (217866_at), score: -0.77
FOXK2forkhead box K2 (203064_s_at), score: -0.97
GMCL1germ cell-less homolog 1 (Drosophila) (218458_at), score: 0.71
GOLPH3golgi phosphoprotein 3 (coat-protein) (217803_at), score: -1
GP1BAglycoprotein Ib (platelet), alpha polypeptide (207389_at), score: 0.71
GPR107G protein-coupled receptor 107 (211979_at), score: -0.66
HIST1H2BHhistone cluster 1, H2bh (208546_x_at), score: 0.73
HIST1H2BIhistone cluster 1, H2bi (208523_x_at), score: 0.66
HSD17B6hydroxysteroid (17-beta) dehydrogenase 6 homolog (mouse) (37512_at), score: 0.81
HSPA12Aheat shock 70kDa protein 12A (214434_at), score: -0.73
KATNB1katanin p80 (WD repeat containing) subunit B 1 (203162_s_at), score: 0.73
KCNN2potassium intermediate/small conductance calcium-activated channel, subfamily N, member 2 (220116_at), score: 0.75
KCTD13potassium channel tetramerisation domain containing 13 (45653_at), score: -0.61
KIAA0317KIAA0317 (202128_at), score: -0.61
KIAA1009KIAA1009 (206005_s_at), score: 0.67
KIAA1305KIAA1305 (220911_s_at), score: -0.69
KPNA6karyopherin alpha 6 (importin alpha 7) (212101_at), score: -0.6
LOC100132540similar to LOC339047 protein (214870_x_at), score: -0.65
LOC100133105hypothetical protein LOC100133105 (214237_x_at), score: 0.73
LOC339047hypothetical protein LOC339047 (221501_x_at), score: -0.68
LRIG1leucine-rich repeats and immunoglobulin-like domains 1 (211596_s_at), score: -0.61
LRP8low density lipoprotein receptor-related protein 8, apolipoprotein e receptor (205282_at), score: 0.68
LRRTM4leucine rich repeat transmembrane neuronal 4 (220345_at), score: -0.64
MAPKAPK3mitogen-activated protein kinase-activated protein kinase 3 (202788_at), score: -0.61
MAST4microtubule associated serine/threonine kinase family member 4 (40016_g_at), score: -0.71
MC4Rmelanocortin 4 receptor (221467_at), score: 0.92
MICAL3microtubule associated monoxygenase, calponin and LIM domain containing 3 (212715_s_at), score: -0.62
MLL4myeloid/lymphoid or mixed-lineage leukemia 4 (203419_at), score: -0.61
NCKAP1NCK-associated protein 1 (217465_at), score: 0.78
NEFMneurofilament, medium polypeptide (205113_at), score: 0.8
NPIPnuclear pore complex interacting protein (204538_x_at), score: -0.64
NUDT11nudix (nucleoside diphosphate linked moiety X)-type motif 11 (219855_at), score: -0.78
OR7E156Polfactory receptor, family 7, subfamily E, member 156 pseudogene (222327_x_at), score: 0.7
PCDH9protocadherin 9 (219737_s_at), score: 0.68
PCDHGA1protocadherin gamma subfamily A, 1 (209079_x_at), score: -0.64
PHC1polyhomeotic homolog 1 (Drosophila) (218338_at), score: -0.81
PIGLphosphatidylinositol glycan anchor biosynthesis, class L (213889_at), score: -0.77
POM121POM121 membrane glycoprotein (rat) (212178_s_at), score: -0.75
PTPN9protein tyrosine phosphatase, non-receptor type 9 (202958_at), score: -0.63
RAB22ARAB22A, member RAS oncogene family (218360_at), score: -0.76
RAD54L2RAD54-like 2 (S. cerevisiae) (213205_s_at), score: -0.79
REREarginine-glutamic acid dipeptide (RE) repeats (200940_s_at), score: -0.82
RNF220ring finger protein 220 (219988_s_at), score: -0.66
RPL18AP6ribosomal protein L18a pseudogene 6 (216383_at), score: 0.72
RPS17P5ribosomal protein S17 pseudogene 5 (216348_at), score: 0.7
SCAMP4secretory carrier membrane protein 4 (213244_at), score: -0.65
SF1splicing factor 1 (208313_s_at), score: -0.63
SIRT6sirtuin (silent mating type information regulation 2 homolog) 6 (S. cerevisiae) (219613_s_at), score: -0.84
SMG7Smg-7 homolog, nonsense mediated mRNA decay factor (C. elegans) (201794_s_at), score: -0.74
SNX27sorting nexin family member 27 (221006_s_at), score: -0.79
SOLHsmall optic lobes homolog (Drosophila) (204275_at), score: -0.75
STAU1staufen, RNA binding protein, homolog 1 (Drosophila) (207320_x_at), score: -0.67
STAU2staufen, RNA binding protein, homolog 2 (Drosophila) (204226_at), score: 0.66
STK3serine/threonine kinase 3 (STE20 homolog, yeast) (204068_at), score: 0.7
TAPBPTAP binding protein (tapasin) (208829_at), score: -0.69
TBC1D2BTBC1 domain family, member 2B (212796_s_at), score: -0.6
TBX3T-box 3 (219682_s_at), score: -0.72
TLE6transducin-like enhancer of split 6 (E(sp1) homolog, Drosophila) (222219_s_at), score: 0.71
TMEM149transmembrane protein 149 (219690_at), score: 0.9
TOP3Atopoisomerase (DNA) III alpha (214300_s_at), score: 0.93
TSKUtsukushin (218245_at), score: -0.95
TTC13tetratricopeptide repeat domain 13 (219481_at), score: 0.66
TXLNAtaxilin alpha (212300_at), score: -0.7
USF2upstream transcription factor 2, c-fos interacting (202152_x_at), score: -0.61
VPS37Bvacuolar protein sorting 37 homolog B (S. cerevisiae) (221704_s_at), score: -0.71
WDR6WD repeat domain 6 (217734_s_at), score: -0.83
WWTR1WW domain containing transcription regulator 1 (202132_at), score: 0.67
XAB2XPA binding protein 2 (218110_at), score: -0.61
YES1v-yes-1 Yamaguchi sarcoma viral oncogene homolog 1 (202932_at), score: -0.6
YPEL1yippee-like 1 (Drosophila) (206063_x_at), score: 0.75
ZDHHC14zinc finger, DHHC-type containing 14 (219247_s_at), score: 0.97
ZFP106zinc finger protein 106 homolog (mouse) (217781_s_at), score: -0.61
ZNF580zinc finger protein 580 (220748_s_at), score: -0.67
Non-Entrez genes
Unknown, score:
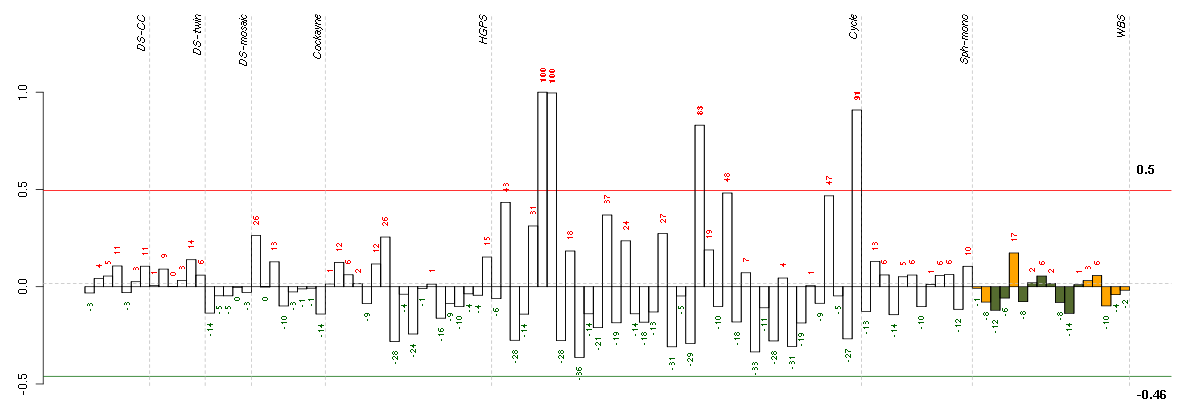
HELP
Conditions in the module, given in the same order as on the expression
plot above. Red color means over-expression, green under-expression in
the given condition.
The barplot below shows the condition (sample) scores. A separate bar
is shown for each sample, its height is the corresponding score of the
sample in the module. The red and green numbers on the bars are the
sample scores expressed in percents, i.e. 100% is 1.0.
The red and green lines show the module thresholds, samples above
the red line and below the green line are included in the module.
The different experiments that were part of the study, are separated
by dashed vertical lines.
— Click on the Help button again to close this help window.
| Id | sample | Experiment | ExpName | Array | Syndrome | Cell.line |
| E-TABM-263-raw-cel-1515486091.cel | 23 | 6 | Cycle | hgu133a2 | none | Cycle 1 |
| E-TABM-263-raw-cel-1515486431.cel | 40 | 6 | Cycle | hgu133a2 | none | Cycle 1 |
| E-TABM-263-raw-cel-1515485771.cel | 7 | 6 | Cycle | hgu133a2 | none | Cycle 1 |
| E-TABM-263-raw-cel-1515485751.cel | 6 | 6 | Cycle | hgu133a2 | none | Cycle 1 |



© 2008-2010 Computational Biology Group, Department of Medical Genetics,
University of Lausanne, Switzerland
