Difference between revisions of "Software"
m |
|||
| (One intermediate revision by one other user not shown) | |||
| Line 1: | Line 1: | ||
| + | [[Category:Homepage]] | ||
| + | |||
== [[ISA|The Iterative Signature Algorithm]] == | == [[ISA|The Iterative Signature Algorithm]] == | ||
| Line 4: | Line 6: | ||
<br/> | <br/> | ||
Large sets of data, like expression profile from many samples, require | Large sets of data, like expression profile from many samples, require | ||
| − | analytic tools to reduce their complexity. | + | analytic tools to reduce their complexity. |
| − | + | The '''Iterative Signature Algorithm (ISA)''' was designed to reduce the | |
| − | |||
| − | |||
| − | |||
| − | The ''' | ||
| − | |||
complexity of very large sets of data by decomposing it into so-called | complexity of very large sets of data by decomposing it into so-called | ||
"modules". In the context of gene expression data these modules consist of | "modules". In the context of gene expression data these modules consist of | ||
| Line 19: | Line 16: | ||
rely on the computation of correlation matrices (like many other tools), it | rely on the computation of correlation matrices (like many other tools), it | ||
is extremely fast even for very large datasets. | is extremely fast even for very large datasets. | ||
| − | |||
'''[[ISA|See more here]]''' | '''[[ISA|See more here]]''' | ||
Revision as of 20:13, 23 February 2012
The Iterative Signature Algorithm
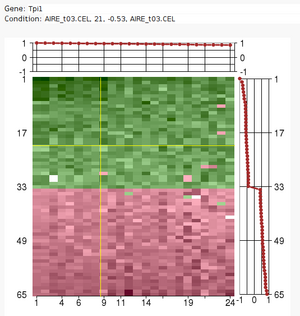
Large sets of data, like expression profile from many samples, require
analytic tools to reduce their complexity.
The Iterative Signature Algorithm (ISA) was designed to reduce the
complexity of very large sets of data by decomposing it into so-called
"modules". In the context of gene expression data these modules consist of
subsets of genes that exhibit a coherent expression profile only over a
subset of microarray experiments. Genes and arrays may be attributed to
multiple modules and the level of required coherence can be varied resulting
in different "resolutions" of the modular mapping. Since the ISA does not
rely on the computation of correlation matrices (like many other tools), it
is extremely fast even for very large datasets.
See more here
ExpressionView
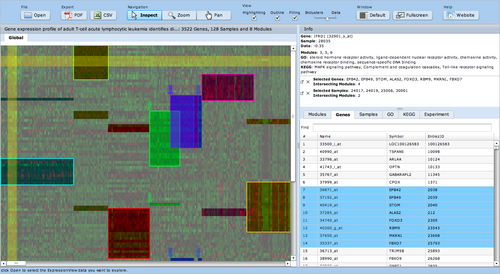
ExpressionView is an R package that provides an interactive environment to explore biclusters identified in gene expression data. A sophisticated ordering algorithm is used to present the biclusters in a visually appealing layout. From this overview, the user can select individual biclusters and access all the biologically relevant data associated with it. The package is aimed to facilitate the collaboration between bioinformaticians and life scientists who are not familiar with the R language.