
Pour pouvoir traiter la grande quantité d’informations à notre disposition, nous avons choisi d’utiliser l’outil informatique. Il s’agit d’un procédé encore peu utilisé en histoire, c’est pour cela que nous allons décrire de façon précise la méthodologie que nous avons suivie.
Dans le traitement informatique de la langue naturelle, la méthode classique est d’utiliser une chaîne de traitement. C’est-à-dire que l’on décompose le travail à effectuer en petites tâches plus simples (en suivant le concept de travail à la chaîne). Chaque tâche utilise le résultat de la précédente et son résultat servira à la prochaine tâche. La première tâche est la numérisation et la dernière est la visualisation.
Schématisation de la chaîne de traitement
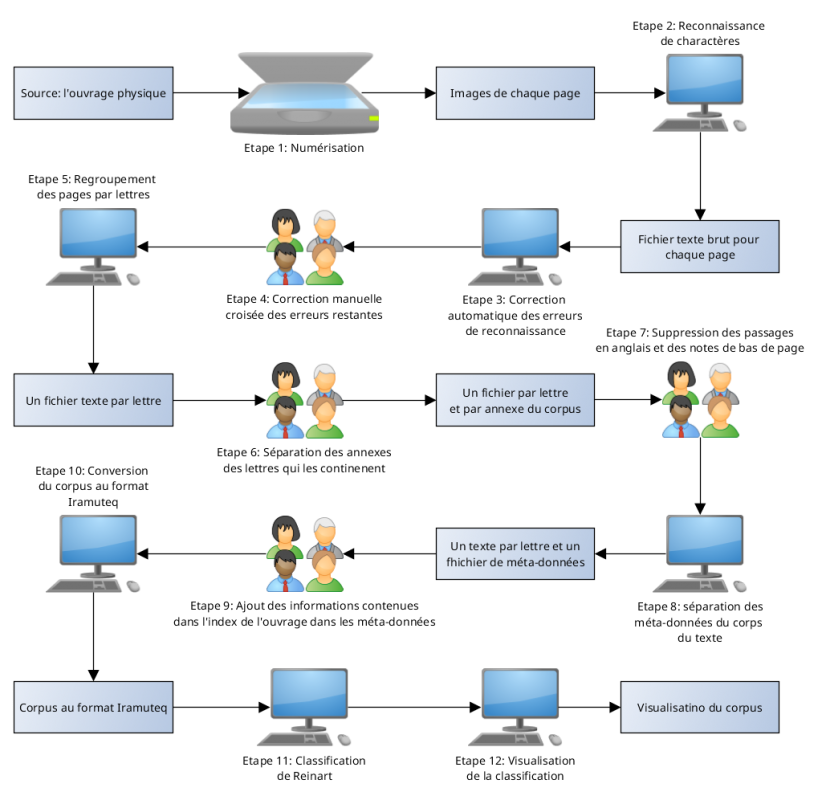 De par la nature ambiguë de la langue naturelle, chaque étape du processus ne peut donner un résultat totalement exact. Par conséquent, chaque tâche introduit son lot d’imprécisions qui s’accumulent tout au long de la chaîne de traitement. Plus problématique, une tâche trop imprécise au début du traitement introduit des erreurs qui, amplifiées par la suite du processus, ont un effet dévastateur sur le résultat final. C’est pour cela que nous avons porté une attention toute particulière à la numérisation et effectué beaucoup de corrections et nettoyages manuels du texte.
De par la nature ambiguë de la langue naturelle, chaque étape du processus ne peut donner un résultat totalement exact. Par conséquent, chaque tâche introduit son lot d’imprécisions qui s’accumulent tout au long de la chaîne de traitement. Plus problématique, une tâche trop imprécise au début du traitement introduit des erreurs qui, amplifiées par la suite du processus, ont un effet dévastateur sur le résultat final. C’est pour cela que nous avons porté une attention toute particulière à la numérisation et effectué beaucoup de corrections et nettoyages manuels du texte.
Le but de tout ce processus est, à partir d’un livre (physique), et de façon assistée, d’extraire les thématiques principales de l’ouvrage, puis de les visualiser afin d’en tirer une interprétation historique.
Le schéma ci-dessus résume la chaîne. On peut distinguer les tâches qui ont été réalisées manuellement et celles qui ont bénéficié d’assistance informatique.